
Một phần để hiểu về Trí tuệ Nhân tạo (AI) là đặt mục tiêu tự xây dựng một mạng lưới thần kinh đơn giản trong Python. Bài viết này sẽ giải thích cách tạo ra mạng neural và bạn có thể dựa vào đó để xây dựng một mạng neural của riêng mình. Cùng với đó, tại cuối bài viết sẽ có một đoạn mã dài và rõ ràng hơn để thực hiện điều này.
Xây dựng mạng neural trong 9 dòng code
from numpy import exp, array, random, dot
training_set_inputs = array([[0, 0, 1], [1, 1, 1], [1, 0, 1], [0, 1, 1]])
training_set_outputs = array([[0, 1, 1, 0]]).T
random.seed(1)
synaptic_weights = 2 * random.random((3, 1)) - 1
for iteration in range(10000):
output = 1 / (1 + exp(-(dot(training_set_inputs, synaptic_weights))))
synaptic_weights += dot(
training_set_inputs.T,
(training_set_outputs - output) * output * (1 - output)
)
print(1 / (1 + exp(-(dot(array([1, 0, 0]), synaptic_weights)))))Trong bài viết này, tôi sẽ giải thích cách tôi xây dựng mạng neural này và bạn cũng có thể sử dụng đoạn mã này để tạo ra một mạng neural của riêng bạn. Tôi cũng sẽ cung cấp một đoạn mã dài hơn, dễ hiểu hơn ở cuối bài viết.
Trước khi đi vào chi tiết, hãy tìm hiểu một chút về mạng lưới thần kinh là gì. Em đồng nghĩa của mạng lưới thần kinh là bộ não con người, với 100 tỷ tế bào thần kinh kết nối với nhau bằng các synaptic. Nếu một synaptic có đủ năng lượng để phát sáng, tế bào thần kinh sẽ phát sáng - truyền dữ liệu đi. Quá trình này được gọi là "suy nghĩ". Chúng ta có thể mô hình hóa quá trình này bằng cách tạo ra một mạng lưới thần kinh trên máy tính. Mặc dù không cần phải mô phỏng cấu trúc phức tạp của não bộ con người ở mức độ tế bào thần kinh, chúng ta vẫn có thể mô hình hóa nó ở mức độ cao hơn bằng cách sử dụng ma trận toán học. Để làm cho nó đơn giản, chúng tôi sẽ chỉ mô hình một tế bào thần kinh đơn giản, với ba đầu vào và một đầu ra.
Chúng ta sẽ đào tạo tế bào thần kinh để giải quyết các vấn đề sau. Bốn ví dụ đầu tiên được gọi là một tập huấn luyện. Bạn có thể đoán quy luật? Đầu "?" có phải là 0 hay 1?
Bạn có thể nhận thấy rằng đầu ra luôn bằng với giá trị của cột đầu vào tận cùng bên trái. Vậy câu trả lời là "ẹ"? Nên được 1.
Quá trình đào tạo
Nhưng làm thế nào để chúng ta dạy cho tế bào thần kinh trả lời đúng câu hỏi? Chúng ta sẽ cung cấp cho mỗi đầu vào một trọng số, có thể là số dương hoặc số âm. Một đầu vào với trọng số càng lớn hoặc trọng số âm càng lớn, tác động lên đầu ra của tế bào thần kinh càng mạnh. Trước khi bắt đầu, chúng ta sẽ đặt mỗi trọng số bằng một số ngẫu nhiên. Sau đó, chúng ta bắt đầu quá trình đào tạo:
- Lấy inputs từ tập dữ liệu huấn luyện, điều chỉnh chúng bằng trọng số, và đưa chúng qua công thức đặc biệt để tính toán đầu ra của tế bào thần kinh.
- Tính toán sai số, đó là sự khác biệt giữa đầu ra của tế bào thần kinh và đầu ra mong muốn đã được cung cấp trong tập huấn luyện.
- Dựa trên hướng dẫn từ sai số, điều chỉnh trọng số một cách nhẹ nhàng.
- Lặp lại quá trình này 10.000 lần.*
Cuối cùng, trọng số của tế bào thần kinh sẽ được điều chỉnh tối ưu với các giá trị trong tập huấn luyện. Nếu chúng ta sử dụng mạng lưới neural này để giải quyết một tình huống mới, nó sẽ áp dụng các trọng số và đưa ra dự đoán. Quá trình này được gọi là "lan truyền ngược" (backpropagation).
Công thức tính đầu ra của tế bào thần kinh
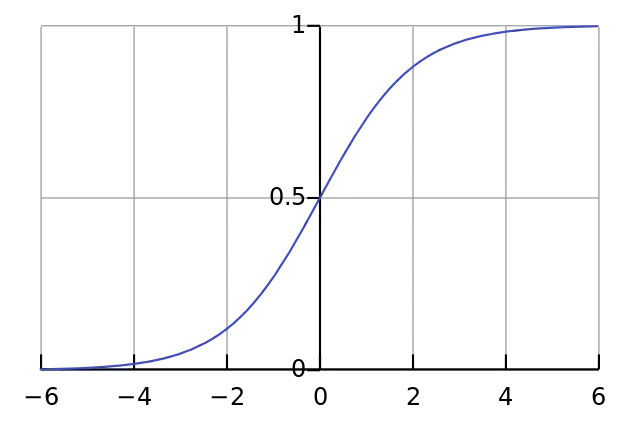
Bạn có thể tự hỏi công thức đặc biệt để tính đầu ra là gì? Đầu tiên, chúng ta sẽ lấy trọng số nhân với dữ liệu đầu vào. Thứ hai, chúng ta sẽ chuẩn hóa kết quả để nằm giữa 0 và 1. Để làm điều này, chúng ta sử dụng một hàm sigmoid toán học. Nếu vẽ nó trên một đồ thị, hàm sigmoid sẽ có dạng đường cong hình chữ "S".
Vì vậy, bằng cách thay thế phương trình đầu tiên vào phương trình thứ hai, công thức cho đầu ra của tế bào thần kinh là:
Output = 1 / (1 + exp(-(dot(đầu vào, trọng số))))Bạn có thể thấy rằng chúng ta không sử dụng ngưỡng tối thiểu hoặc hàm kích hoạt để xác định xem tế bào thần kinh có phát sáng hay không. Điều này giúp giữ mọi thức đơn giản.
Công thức điều chỉnh trọng số
Trong suốt quá trình đào tạo, chúng ta điều chỉnh trọng số. Nhưng làm thế nào để điều chỉnh? Chúng ta có thể sử dụng công thức "Error Weighted Derivative":
Điều chỉnh = dot(đầu vào.T, sai số * đạo hàm sigmoid(output))Vậy tại sao chúng ta lại sử dụng công thức này? Đầu tiên, chúng ta muốn thực hiện điều chỉnh tỷ lệ thuận với lỗi (tức là điều chỉnh mạnh mẽ hơn khi sai số càng lớn). Thứ hai, chúng ta nhân với đầu vào, đó là 0 hoặc 1. Nếu đầu vào là 0, trọng số không cần điều chỉnh. Cuối cùng, chúng ta nhân với đạo hàm của đường cong sigmoid. Để hiểu rõ hơn, hãy để tôi giải thích:
- Chúng ta sử dụng đường cong sigmoid để tính đầu ra của tế bào thần kinh.
- Nếu đầu ra là một số dương hoặc âm lớn, điều đó có nghĩa là tế bào thần kinh rất tự tin.
- Từ hình ảnh, chúng ta có thể thấy rằng nếu giá trị trục x tiến tới âm vô cùng hoặc dương vô cùng, đường cong sigmoid sẽ có độ dốc gần như bằng phẳng.
- Nếu tế bào thần kinh tự tin rằng trọng số hiện tại là chính xác, nó không muốn điều chỉnh nhiều. Vậy nên, chúng ta nhân với độ dốc của đường cong sigmoid để đạt được điều này.
Độ dốc của đường cong sigmoid có thể được tính bằng cách lấy đạo hàm:
Đạo hàm sigmoid(x) = x * (1 - x)Vậy, bằng cách thay phương trình thứ hai vào phương trình đầu tiên, công thức cuối cùng để điều chỉnh trọng số là:
Điều chỉnh = dot(đầu vào.T, sai số * đạo hàm sigmoid(output))Tuy có nhiều công thức khác có thể làm cho mạng neural học nhanh hơn, công thức chúng ta sử dụng có lợi thế là đơn giản.
Xây dựng mã Python
Mặc dù chúng ta không sử dụng thư viện mạng neural nào, chúng ta sử dụng 4 phương thức từ thư viện numpy của Python. Đó là:
exp- tính lũy thừa tự nhiên (natural exponential)array- tạo ma trận (creates a matrix)dot- nhân ma trận (multiplies matrices)random- sinh số ngẫu nhiên (gives us random numbers)
Ví dụ, chúng ta có thể sử dụng phương thức array() để biểu diễn tập dữ liệu huấn luyện như sau:
training_set_inputs = array([[0, 0, 1], [1, 1, 1], [1, 0, 1], [0, 1, 1]])
training_set_outputs = array([[0, 1, 1, 0]]).TDưới đây là một ví dụ hoàn chỉnh được viết bằng Python:
from numpy import exp, array, random, dot
class NeuralNetwork():
def __init__(self):
# Seed the random number generator, so it generates the same numbers
# every time the program runs.
random.seed(1)
# We model a single neuron, with 3 input connections and 1 output connection.
# We assign random weights to a 3 x 1 matrix, with values in the range -1 to 1
# and mean 0.
self.synaptic_weights = 2 * random.random((3, 1)) - 1
# The Sigmoid function, which describes an S shaped curve.
# We pass the weighted sum of the inputs through this function to
# normalise them between 0 and 1.
def __sigmoid(self, x):
return 1 / (1 + exp(-x))
# The derivative of the Sigmoid function.
# This is the gradient of the Sigmoid curve.
# It indicates how confident we are about the existing weight.
def __sigmoid_derivative(self, x):
return x * (1 - x)
# We train the neural network through a process of trial and error.
# Adjusting the synaptic weights each time.
def train(self, training_set_inputs, training_set_outputs, number_of_training_iterations):
for iteration in range(number_of_training_iterations):
# Pass the training set through our neural network (a single neuron).
output = self.think(training_set_inputs)
# Calculate the error (The difference between the desired output
# and the predicted output).
error = training_set_outputs - output
# Multiply the error by the input and again by the gradient of the Sigmoid curve.
# This means less confident weights are adjusted more.
# This means inputs, which are zero, do not cause changes to the weights.
adjustment = dot(training_set_inputs.T, error * self.__sigmoid_derivative(output))
# Adjust the weights.
self.synaptic_weights += adjustment
# The neural network thinks.
def think(self, inputs):
# Pass inputs through our neural network (our single neuron).
return self.__sigmoid(dot(inputs, self.synaptic_weights))
if __name__ == "__main__":
# Initialise a single neuron neural network.
neural_network = NeuralNetwork()
print("Random starting synaptic weights:")
print(neural_network.synaptic_weights)
# The training set. We have 4 examples, each consisting of 3 input values
# and 1 output value.
training_set_inputs = array([[0, 0, 1], [1, 1, 1], [1, 0, 1], [0, 1, 1]])
training_set_outputs = array([[0, 1, 1, 0]]).T
# Train the neural network using a training set.
# Do it 10,000 times and make small adjustments each time.
neural_network.train(training_set_inputs, training_set_outputs, 10000)
print("New synaptic weights after training:")
print(neural_network.synaptic_weights)
# Test the neural network with a new situation.
print("Considering new situation [1, 0, 0] -> ?: ")
print(neural_network.think(array([1, 0, 0])))Bài viết đã được tham khảo từ nguồn ở đây. Link Source Code Here.
{kind=link}