Bài viết được sáng tác bởi Phạm Huy Hoàng
Hãy ôn lại các kiến thức cơ bản về thuật toán và các cấu trúc dữ liệu thay vì chỉ tập trung vào những công nghệ phức tạp. Kiến thức về thuật toán không chỉ giúp bạn viết code thông minh hơn mà còn giúp tăng tốc độ xử lý. Ngoài ra, trong phỏng vấn, các công ty cũng thích hỏi về thuật toán.
Dù có rất nhiều thuật toán và cấu trúc dữ liệu, chúng ta chỉ cần tập trung vào 8 cấu trúc dữ liệu cơ bản này. 96,69% các bài phỏng vấn trong chương trình Leetcode và thuật toán đều dựa trên 8 cấu trúc dữ liệu này, và có thể có một số biến thể. Nắm vững 8 cấu trúc dữ liệu này và biết cách sử dụng chúng là một kiến thức kha khá cho bạn.
Ôn Lại Về Độ Phức Tạp Của Thuật Toán
Độ phức tạp của thuật toán (biểu diễn bằng Big-O Notation) là một biểu thức mô tả hành vi của thuật toán khi kích thước dữ liệu thay đổi. Big O mô tả mối liên hệ giữa số lượng phần tử đầu vào và số lượng bước tính toán hoặc lượng bộ nhớ mà thuật toán sử dụng.
Hãy nhìn vào hình dưới đây để hiểu rõ hơn:
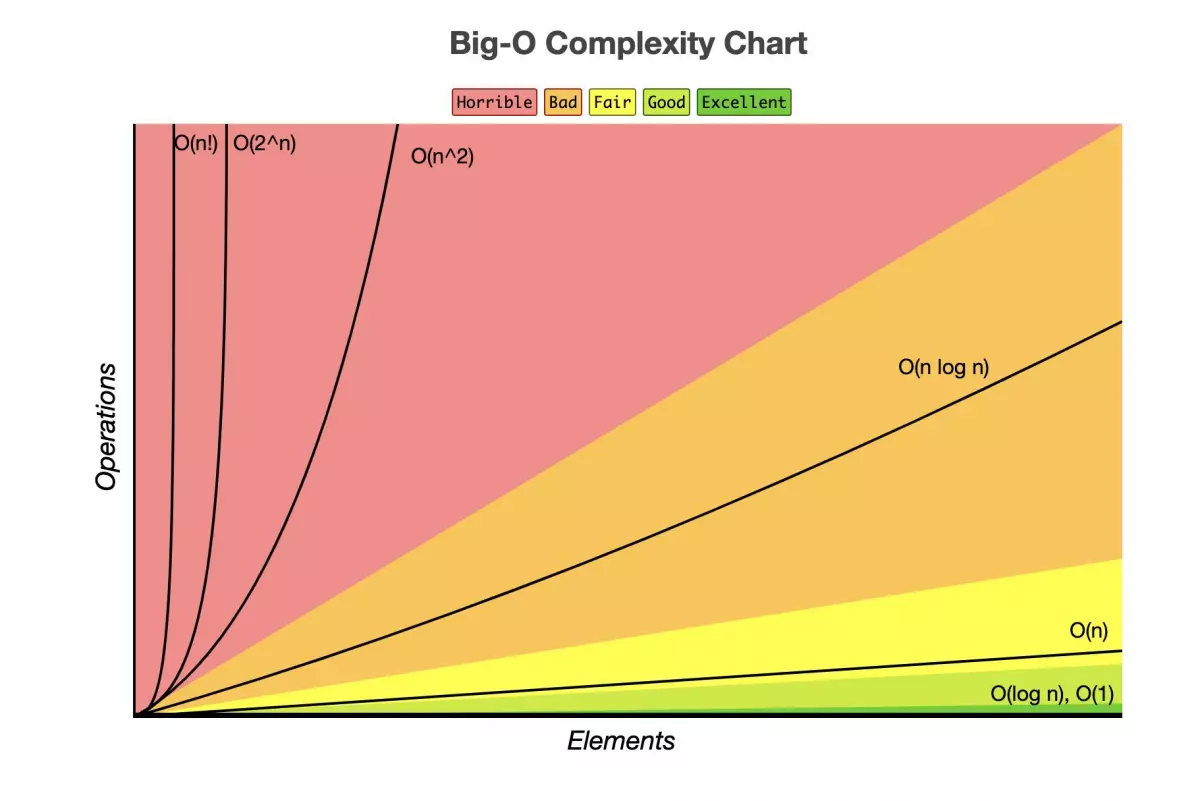
Với các thuật toán có độ phức tạp là O(n), khi dữ liệu đầu vào có 10 phần tử, chương trình phải chạy 10 bước. Khi số lượng dữ liệu đầu vào tăng gấp đôi, thì số lượng bước cũng tăng gấp đôi. Nếu độ phức tạp là O(n²), khi số lượng dữ liệu đầu vào tăng gấp đôi, số lượng bước tăng lên gấp 4 lần. Tóm lại, thuật toán có độ phức tạp càng lớn, thì khi số lượng dữ liệu càng nhiều, nó sẽ chạy càng chậm.
Ví dụ, với bài toán duyệt qua nhiều thành phố để đưa thư (traveling salesman problem), nếu dùng thuật toán vét cạn có độ phức tạp là O(n!), thì khi có hàng ngàn địa điểm, thì thậm chí máy tính cũng không thể xử lý được trong thời gian ngắn.
Phân Biệt Time Và Space Complexity
Big-O Notation có thể được sử dụng để đo thời gian chạy (số lượng bước chạy) và lượng bộ nhớ mà thuật toán cần sử dụng. Để phân biệt dễ dàng, ta chia làm hai loại:
- Time Complexity: Số lượng bước chạy - thời gian chạy của thuật toán dựa trên số lượng phần tử đầu vào.
- Space Complexity: Số lượng bộ nhớ mà thuật toán cần dựa trên số lượng phần tử đầu vào.
Giả sử bạn cần giải quyết bài toán Two Sum đơn giản: Cho một mảng gồm N số không trùng nhau, hãy tìm hai số trong mảng có tổng bằng X.
Bạn có thể giải quyết bài toán theo hai cách:
- Cách 1: Sử dụng hai vòng lặp để duyệt qua tất cả các cặp phần tử trong mảng.
- Cách này không tốn thêm bộ nhớ, nhưng time complexity là O(n²) vì ta phải chạy hai vòng lặp lồng nhau, mỗi vòng lặp gồm n phần tử.
- Cách 2: Duyệt qua từng phần tử, lưu các phần tử đã duyệt qua vào một tập hợp (set). Mỗi khi gặp một phần tử có giá trị A, tính giá trị B = X - A, sau đó kiểm tra xem trong tập hợp có giá trị B hay không.
- Cách này chỉ cần lặp qua mảng một lần, nên time complexity là O(n).
- Tuy nhiên, bạn phải cần thêm bộ nhớ để lưu các phần tử vào tập hợp, nên space complexity là O(n).
Tóm lại, cách 2 sẽ chạy nhanh hơn cách 1, nhưng sẽ tốn nhiều bộ nhớ hơn. Điều này cho thấy tầm quan trọng của việc nắm vững các cấu trúc dữ liệu cơ bản và độ phức tạp của các thao tác của chúng. Chúng sẽ giúp bạn tìm ra cách giải quyết tối ưu cho từng bài toán, cả trong công việc lẫn trong phỏng vấn.
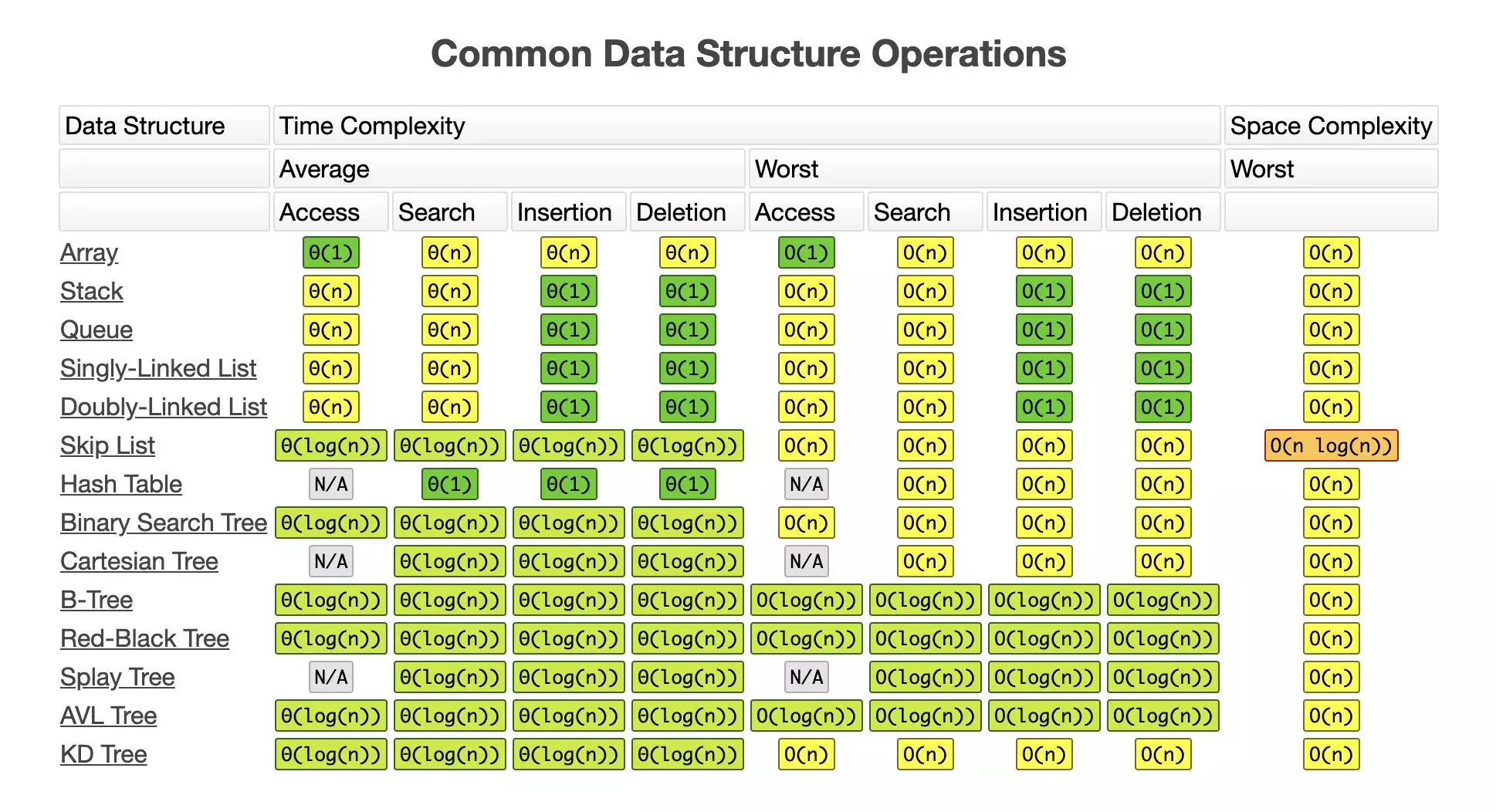 Độ phức tạp của các operation (thêm, xoá, tìm kiếm) của các cấu trúc dữ liệu phổ biến
Độ phức tạp của các operation (thêm, xoá, tìm kiếm) của các cấu trúc dữ liệu phổ biến
Tại Sao Lại Để Ra Nhiều Thuật Toán/Cấu Trúc Dữ Liệu Quá?
Có lẽ bạn đã tự hỏi "Tại sao lại có nhiều cấu trúc dữ liệu, nhiều thuật toán như vậy" phải không?
Ở phần này, bạn đã hiểu rồi đấy! Mỗi thuật toán sẽ có time/space complexity khác nhau và giải quyết các vấn đề khác nhau. Trong một vấn đề cụ thể, việc sử dụng thuật toán A và cấu trúc dữ liệu A sẽ nhanh hơn và tiết kiệm tài nguyên hơn so với việc sử dụng thuật toán B và cấu trúc dữ liệu B.
Khi tham gia phỏng vấn, bạn thường nghĩ ra một phương pháp brute-force, chạy chậm nhất nhưng có thể giải quyết vấn đề. Sau đó, bạn sẽ tìm cách tối ưu hóa, sử dụng thuật toán/cấu trúc dữ liệu phù hợp để giảm time/space complexity và đạt được kết quả tối ưu nhất.
Chính vì vậy, việc nắm vững các cấu trúc dữ liệu cơ bản, độ phức tạp của các thao tác là rất quan trọng. Chúng sẽ giúp bạn tìm ra cách giải quyết tối ưu cho một bài toán, không chỉ trong công việc mà còn trong phỏng vấn. (Thậm chí kỹ thuật cache mà chúng ta sử dụng hàng ngày đã dựa trên cấu trúc dữ liệu HashTable, tốn thêm bộ nhớ để giảm thời gian tính toán dữ liệu).
Tạm Kết
Vì bài viết đã dài, nên ở phần này, chúng ta chỉ ôn lại sơ về Big-O Notation, Time/Space Complexity của một thuật toán, cấu trúc dữ liệu. Trong hai phần tiếp theo, tôi sẽ giới thiệu kỹ hơn về 8 cấu trúc dữ liệu cơ bản, cách sử dụng chúng trong các trường hợp cụ thể và một số bài toán phổ biến để mọi người cùng luyện tập.
Note: Môn học thuật toán trong trường Đại học dạy cả những biểu thức khác như Big-Omega, Big Theta, Small O,... Tuy nhiên, sau vài năm làm việc, tôi chưa từng sử dụng chúng, nên tôi sẽ bỏ qua trong bài viết này.
Article originally published on toidicodedao
Có thể bạn quan tâm:
- Tái cấu trúc mã nguồn: Trừu tượng hóa
- Design pattern là gì? Tại sao nên sử dụng Design pattern?
- Nginx và Apache là gì? So sánh Nginx và Apache
Tham khảo thêm các vị trí tuyển dụng trong ngành IT tại Topdev