

 Hình ảnh: Data pipeline - Weld Data Dictionary
Hình ảnh: Data pipeline - Weld Data Dictionary
Trong thời đại số ngày nay, nhu cầu quản lý và xử lý dữ liệu vô cùng quan trọng. Đó chính là lý do Data Pipeline, hay đường ống dữ liệu, trở nên ngày càng phổ biến trong các dự án khoa học dữ liệu và phân tích kinh doanh. Trên thực tế, Data Pipeline đã trở thành một công cụ không thể thiếu để xây dựng một hệ thống dữ liệu đáng tin cậy và hiệu quả.
Data Pipeline là gì?
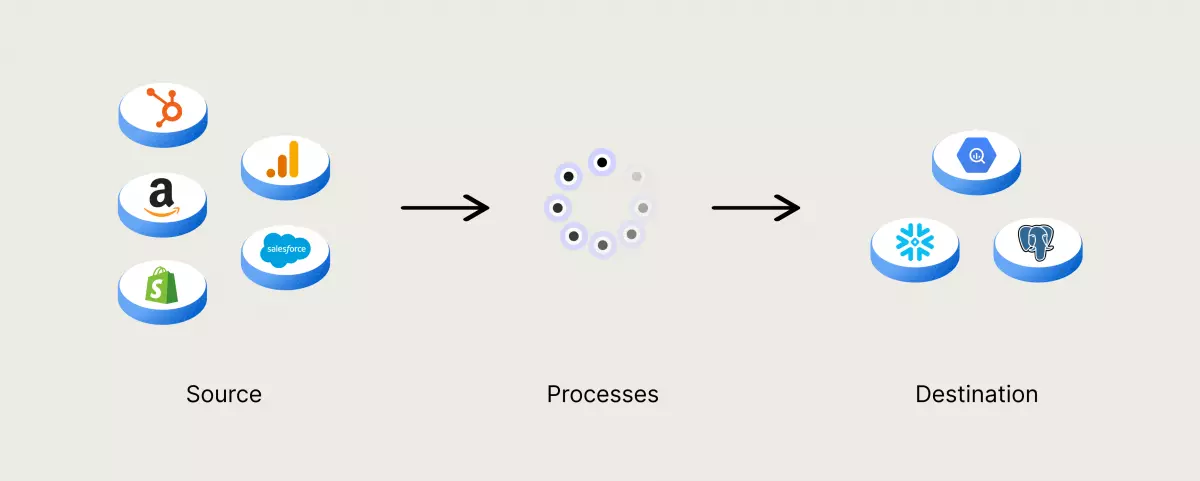
Data Pipeline, hay còn được gọi là đường ống dữ liệu, là một phương pháp để nhập dữ liệu từ nhiều nguồn khác nhau và chuyển đến kho lưu trữ dữ liệu để phân tích. Trước khi được lưu trữ, dữ liệu cần được xử lý, bao gồm chuyển đổi, lọc, điều chỉnh và tiêu chuẩn hóa, đảm bảo tích hợp và đồng nhất. Một kho lưu trữ dữ liệu được yêu cầu có một cấu trúc dữ liệu thống nhất, các cột và loại dữ liệu phải được đồng nhất để dễ dàng cập nhật dữ liệu mới.
Data Pipeline đóng vai trò như "đường ống" cho các dự án khoa học dữ liệu hoặc phân tích thông tin kinh doanh. Dữ liệu được lấy từ nhiều nguồn khác nhau như API, cơ sở dữ liệu SQL và NoSQL, tệp tin, ... Tuy nhiên, dữ liệu này thường không được sử dụng trực tiếp. Thay vào đó, các nhà khoa học dữ liệu hoặc kỹ sư dữ liệu phải làm việc để chuẩn bị dữ liệu và xây dựng cấu trúc phù hợp với nhu cầu kinh doanh. Cách xử lý dữ liệu được xác định bởi sự kết hợp giữa phân tích dữ liệu và yêu cầu kinh doanh. Khi dữ liệu đã được lọc, hợp nhất và tổng hợp một cách chính xác, dữ liệu đó có thể được lưu trữ và sử dụng cho mục đích phân tích, trực quan hóa, và học máy.
Các loại Data Pipelines
Data Pipelines có hai loại chính: Batch Processing (xử lý hàng loạt) và Streaming Data (truyền dữ liệu).
Batch Processing
Batch Processing là một bước quan trọng để xây dựng cơ sở hạ tầng dữ liệu đáng tin cậy. Các công việc xử lý hàng loạt này thường được lên lịch trong giờ làm việc ngoài cao điểm để không ảnh hưởng đến các công việc khác. Xử lý hàng loạt thường là phương pháp tối ưu cho việc xử lý lượng lớn dữ liệu, ví dụ như việc kế toán hàng tháng. Các công việc xử lý hàng loạt được tổ chức dưới dạng một chuỗi lệnh, trong đó kết quả của một lệnh trở thành đầu vào của lệnh tiếp theo.
Streaming Data
Streaming Data được sử dụng để xử lý dữ liệu được tạo liên tục và cần được xử lý ngay khi nó được tạo ra. Ví dụ, các ứng dụng ghi nhận lịch sử bán hàng và hàng tồn kho cần dữ liệu thời gian thực để cập nhật. Tuy nhiên, việc xử lý dữ liệu theo luồng có thể không đáng tin cậy như các hệ thống xử lý hàng loạt do những thông điệp có thể bị bỏ qua hoặc mất trong quá trình xử lý. Để giải quyết vấn đề này, dịch vụ tin nhắn được sử dụng để xác nhận việc xử lý tin nhắn và đảm bảo không có thông điệp nào bị mất.
Kiến trúc Data Pipeline
Kiến trúc của Data Pipeline bao gồm 3 bước chính: nhập dữ liệu, chuyển đổi dữ liệu và lưu trữ dữ liệu.
Nhập dữ liệu
Dữ liệu được lấy từ nhiều nguồn khác nhau, bao gồm cả dữ liệu có cấu trúc và dữ liệu không có cấu trúc. Trong dữ liệu phát trực tuyến, các nguồn dữ liệu này thường được gọi là nhà sản xuất. Thay vì trích xuất dữ liệu ngay khi nó có sẵn, việc đưa dữ liệu thô vào một kho dữ liệu đám mây trước đó là một ý tưởng tốt. Điều này cho phép cập nhật lịch sử dữ liệu nếu có sự điều chỉnh trong quá trình xử lý dữ liệu.
Chuyển đổi dữ liệu
Bước này bao gồm các thao tác để xử lý dữ liệu và đưa dữ liệu vào định dạng được yêu cầu bởi kho lưu trữ dữ liệu. Các công việc này sẽ được tự động hoá và thay thế cho các công việc lặp đi lặp lại. Ví dụ, báo cáo kinh doanh yêu cầu dữ liệu được làm sạch và chuyển đổi theo một cách thống nhất.
Lưu trữ dữ liệu
Dữ liệu đã được chuyển đổi sẽ được lưu trữ trong kho lưu trữ dữ liệu, nơi mà dữ liệu có thể được trình bày và truy cập bởi các bên liên quan. Trong dữ liệu phát trực tuyến, dữ liệu đã được chuyển đổi này thường được gọi là người tiêu dùng.
Ứng dụng của Data Pipeline
Data Pipeline có nhiều ứng dụng hữu ích trong thực tế. Dưới đây là 3 ứng dụng chính của nó:
1. Trực quan hóa dữ liệu
Trực quan hóa dữ liệu là cách thức biểu diễn dữ liệu thông qua biểu đồ, sơ đồ, infographics, hoạt ảnh, ... Điều này giúp người dùng dễ dàng hiểu các mối quan hệ dữ liệu và nhận thấy các thông tin quan trọng.
2. Học máy
Học máy là một lĩnh vực trong trí tuệ nhân tạo và khoa học máy tính, tập trung vào việc sử dụng dữ liệu và thuật toán để mô phỏng cách con người học hỏi và nâng cao hiệu suất dự đoán. Được sử dụng để phân loại hoặc dự đoán dựa trên các thuật toán và phương pháp thống kê.
3. Phân tích khám phá dữ liệu
Phân tích khám phá dữ liệu (EDA) được các nhà khoa học dữ liệu sử dụng để phân tích và khám phá các tập dữ liệu và tóm tắt các đặc điểm chính của chúng. Phân tích khám phá dữ liệu giúp xác định cách tốt nhất để thao tác các nguồn dữ liệu và khám phá các mẫu, phát hiện sự bất thường và kiểm tra các giả thuyết.
Dữ liệu đã trở thành tài nguyên quý giá trong thời đại số. Với Data Pipeline, chúng ta có công cụ hữu ích để xử lý, quản lý và phân tích dữ liệu một cách hiệu quả. Dễ dàng nhìn thấy ưu điểm của Data Pipeline, liệu bạn có sẵn sàng áp dụng công nghệ này vào công việc của mình không?
Xem thêm:
- Khóa học Data Storytelling
- [Tài liệu miễn phí] Nhập môn Excel cho Kỹ sư xây dựng
- [Tài liệu miễn phí] Phím tắt Excel cho Windows và Mac
- [Tài liệu miễn phí] Hướng dẫn tạo mô hình tài chính











