

Trong deep learning, mỗi mô hình đều sử dụng các layer có chức năng đặc trưng để giải quyết các tác vụ cụ thể. Ví dụ, trong xử lý ảnh, chúng ta thường sử dụng mạng CNN (convolutional neural network) để trích xuất đặc trưng trên các vùng cục bộ của ảnh như các đường nét chính như dọc, ngang, chéo, v.v. Hoặc layer LSTM (long short term memory) được sử dụng trong các mô hình dịch máy và phân loại cảm xúc văn bản (sentiment analysis). Tuy nhiên, còn rất nhiều các layer khác trong deep learning và hiểu được chúng là rất quan trọng.
Time Distributed
Layer Time Distributed trong deep learning có chức năng phân phối dữ liệu theo thời gian. Ví dụ, trong dự báo dạng chuỗi thông qua mạng RNN, chúng ta cần hiểu kiến trúc mạng RNN dựa trên layer LSTM. Ta có một số dạng dự báo của RNN như sau:
 Hình 1: Các dạng dự báo trong RNN
Hình 1: Các dạng dự báo trong RNN
- One to one: Chỉ có 1 input và trả ra 1 output.
- One to many: Chỉ có 1 input. Véc tơ context ở bước t+1 và kết hợp với output dự báo ở bước t để dự báo output ở bước t+1. Quá trình này được lặp lại cho đến hết chuỗi, từ 1 input ta có một chuỗi outputs.
- Many to one: Trả ra kết quả là véc tơ output tại time step cuối cùng trong mạng LSTM.
- Many to many: Kiến trúc đặc trưng của model dịch máy. Input là véc tơ embedding một từ của ngôn ngữ nguồn và trả kết quả đầu ra là một véc tơ phân phối xác suất của từ output ở ngôn ngữ đích.
Khi áp dụng các layer RNN trong các bài toán xử lý ngôn ngữ tự nhiên (NLP), chúng ta thường có 2 lựa chọn:
Lựa chọn 1: Trả ra chỉ kết quả là hidden layer cuối cùng.
Lựa chọn 2: Trả ra chuỗi các hidden layer ở mỗi time step.
Tiếp theo, chúng ta cần áp dụng các fully connected layers có kiến trúc như một mạng MLP thông thường. Kết quả trả về là dự báo phân phối xác suất nhãn. Nhưng làm thế nào chúng ta áp dụng các fully connected layers cho từng lựa chọn? Đối với lựa chọn 1, ta dễ dàng truyền qua một Dense Layer (hay còn gọi là fully connected layer) thông thường và xây dựng một chuỗi fully connected layers. Tuy nhiên, đối với lựa chọn 2, ta cần kết hợp một Dense Layer với một chuỗi các hidden layer như output của trường hợp many to many và one to many. Khi đó, ta cần một layer đặc biệt hơn, không chỉ có tác dụng như dense layer trong mạng MLP mà còn có tác dụng kết nối tới từng hidden layer ở mỗi thời gian, đó chính là Time Distributed Layers.
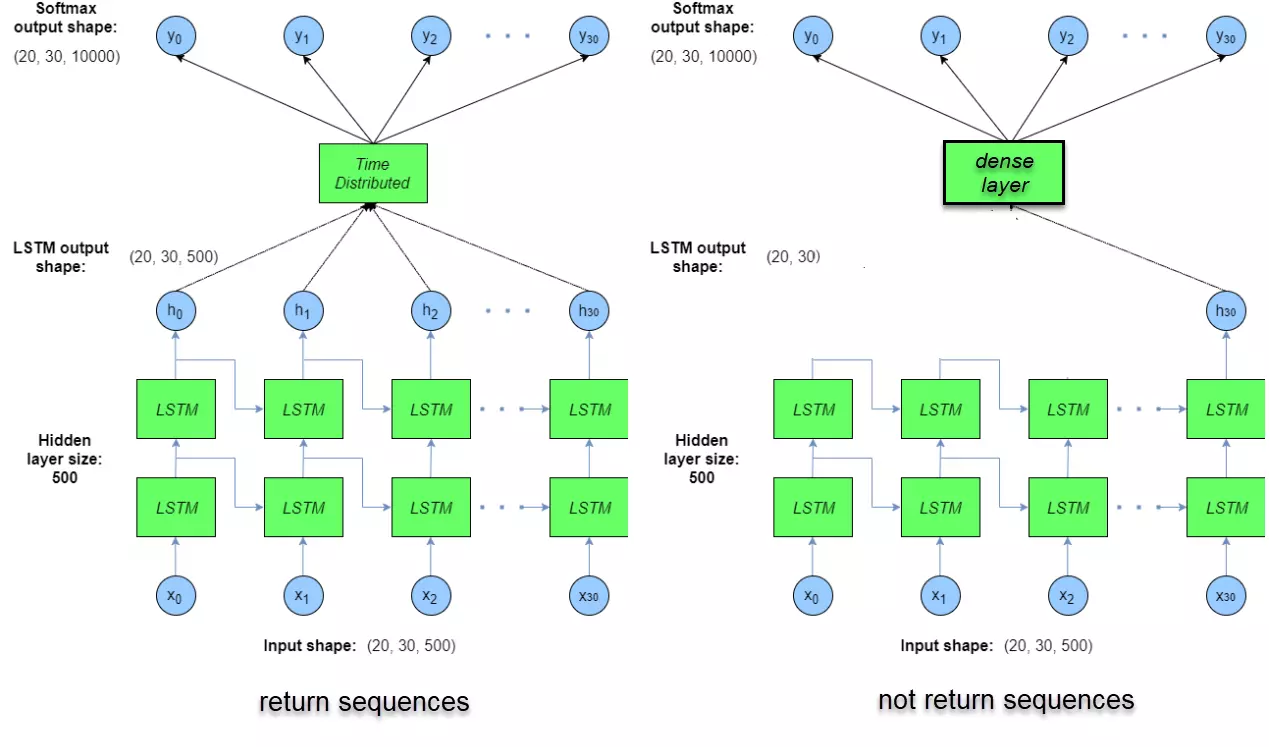
Để hình dung rõ hơn, ta có thể xem hình so sánh dưới đây giữa Time Distributed Layer và Dense Layer.
Hình 2: So sánh giữa Time Distributed Layer và Dense Layer
Như vậy, bản chất của Time Distributed Layer không khác gì một Dense Layer thông thường. Do đó, trong một issue của fchollet, tác giả của thư viện Keras, đã giải thích một cách ngắn gọn nhưng khá khó hiểu đối với người mới bắt đầu:
"TimeDistributedDense applies a same Dense (fully-connected) operation to every timestep of a 3D tensor."
Time Distributed Layer cũng được sử dụng rất nhiều trong các mô hình xử lý video. Giả sử ta có một batch video gồm các khung hình 5 chiều: (batch_size, time, width, height, channels). Để áp dụng một mạng tích chập 2 chiều lên toàn bộ các khung hình theo thời gian, ta cần sử dụng Time Distributed để thu được output shape mới là (batch_size, new_width, new_height, output_channels).
Ngoài ra, Time Distributed Layer còn được sử dụng trong các mô hình phân loại nội dung video một cách hiệu quả. Tôi sẽ hướng dẫn bạn nếu có cơ hội.
Tính năng Batch Normalization
Layer Batch Normalization trong deep learning được sử dụng để chuẩn hóa dữ liệu ở các layer theo batch về phân phối chuẩn. Layer này thường được áp dụng sau Convolutional layer và thường nằm ở vị trí ban đầu của mô hình để đạt hiệu quả cao nhất. Mục đích chính của Batch Normalization là giúp quá trình gradient descent hội tụ nhanh hơn.
Để hiểu rõ hơn về cách áp dụng và hiệu quả của Batch Normalization, chúng ta sẽ thử xây dựng mô hình LeNet với và không có Batch Normalization và so sánh kết quả sau khi huấn luyện. Bộ dữ liệu chúng ta sử dụng là MNIST, gồm các bức ảnh kích thước 28 x 28 của 10 chữ số từ 0 đến 9.
Bước 1: Load dữ liệu từ keras
Trước hết, chúng ta cần kiểm tra phân phối số quan sát trên các nhóm.
Vì input của mạng LeNet có kích thước 32 x 32 nên chúng ta cần thêm padding để có kích thước đó. Việc này thực hiện dễ dàng như sau:
LeNet là mạng CNN đơn giản được tạo ra vào năm 1998 bởi Yan LeCun. Mạng này sử dụng các layer tích chập (Convolutional) kết hợp với MaxPooling để giảm chiều dữ liệu mà không thay đổi các đặc trưng của ảnh. Kiến trúc chi tiết như sau:
Hình 3: Kiến trúc mạng LeNet
Chúng ta khởi tạo mô hình LeNet không sử dụng Batch Normalization.
Tiếp theo, chúng ta huấn luyện mô hình LeNet khi không sử dụng Batch Normalization.
Chúng ta cũng có thể khởi tạo mô hình LeNet khi sử dụng Batch Normalization.
Sau đó, chúng ta huấn luyện mô hình với Batch Normalization.
Kết quả cho thấy, mô hình khi sử dụng Batch Normalization hội tụ nhanh hơn và có độ chính xác cao hơn so với mô hình không sử dụng Batch Normalization. Điều này cho thấy cơ chế chuẩn hóa dữ liệu sau mỗi layer đã giúp các tham số hội tụ nhanh hơn. Một thay đổi nhỏ nhưng mang lại hiệu quả bất ngờ.
Attention Layer
Trong vài năm gần đây, độ chính xác của các mô hình dịch máy đã được cải thiện đáng kể nhờ một layer đặc biệt có tác dụng phân bố lại trọng số attention weight của các từ input lên từ output sao cho càng ở vị trí gần thì trọng số càng cao.
Cụ thể, thuật toán attention cho phép phân bố lại trọng số attention của mỗi từ input lên từ output. Tôi đã giới thiệu chi tiết về thuật toán attention trong một bài trước. Attention được sử dụng chủ yếu trong mô hình Seq2Seq.
Hiện nay, layer attention được khởi tạo trong TensorFlow 2.0 dựa trên kiến trúc key-value attention. Các bạn có thể tham khảo trong tài liệu Attention Layer của TensorFlow 2.0. Layer này cũng cho phép sử dụng các layer mask như query_mask và value_mask để loại bỏ attention tại một số vị trí nhất định trong query hoặc value.
Attention Layer rất mạnh trong việc nắm bắt các liên kết dài của chuỗi các từ trong câu và khắc phục nhược điểm của các mô hình Recurrent Neural Network.
Trong TensorFlow 2.0, chúng ta thậm chí có thể áp dụng Attention Layer vào mô hình LSTM để phân loại email spam và so sánh hiệu quả với việc áp dụng các layer như Time Distributed Layer và Dense Layer.
Kết quả cho thấy, khi áp dụng Attention Layer vào mô hình phân loại email, độ chính xác của mô hình cao hơn. Ngay từ những epoch đầu tiên, mô hình đã đạt được độ chính xác gần như hoàn hảo. Attention Layer rất mạnh trong việc nắm bắt các liên kết dài của chuỗi các từ trong câu và khắc phục được nhược điểm về sự phụ thuộc dài hạn kém của các mô hình Recurrent Neural Network.
Như vậy, đây là những layers quan trọng trong deep learning mà chúng ta cần nắm vững. Tôi hy vọng các bạn có thể áp dụng tốt những layers này vào các bài toán của mình để nâng cao hiệu quả của mô hình.











