

Trong loạt bài viết "Giới thiệu về phép nhúng từ", chúng ta đã khám phá phần 1 về khái niệm và công dụng của phép nhúng từ. Cũng như cùng nhau tìm hiểu về hai mô hình nhúng từ cơ bản là BoW và TF-IDF.
Trong phần 2 này, chúng ta sẽ tiếp tục khám phá các phép nhúng từ phức tạp hơn, xuất hiện trong thời kỳ học sâu trở nên phổ biến trong những năm gần đây.
3. Các phép nhúng từ thông dụng (tiếp theo)
c) Word2Vec
Word2Vec (Word to vector) là phương pháp được công bố bởi Google vào năm 2013. Bằng cách dự đoán từ xuất hiện trong một phạm vi từ xung quanh (cửa sổ ngữ cảnh), Word2Vec học được ma trận nhúng từ W[V x N], trong đó:
- V là số lượng từ vựng.
- N là số đặc trưng.
Phương pháp Word2Vec đề xuất hai cách để huấn luyện ma trận nhúng từ là Túi từ liên tục (Continuous Bag of Words - CBOW) và Skip-gram. CBOW thường có thời gian huấn luyện nhanh hơn, trong khi Skip-gram có khả năng biểu diễn các từ hiếm gặp tốt hơn. Skip-gram thường được sử dụng chung với phương pháp Lấy mẫu phủ định (negative sampling) để tăng hiệu suất, đặc biệt khi làm việc với dữ liệu lớn.
Dưới đây là hình minh họa cho CBOW và Skip-gram cơ bản:
 Hình minh họa cho CBOW và Skip-gram cơ bản (Nguồn)
Hình minh họa cho CBOW và Skip-gram cơ bản (Nguồn)
d) FastText
FastText là thư viện mã nguồn mở do Facebook tạo ra năm 2016, hỗ trợ huấn luyện phép nhúng từ và phân loại văn bản. FastText được viết bằng ngôn ngữ C++ 11, có thể chạy đa luồng, trừ khi đọc dữ liệu. FastText là một dạng mở rộng của Word2Vec và khác biệt ở chỗ nó sử dụng các n-gram để học. Ví dụ, từ "đồng" với n-gram=3 sẽ được tách thành ["<đồng>", "<đồ", "đồn", "ồng", "ng>"]. Dấu "<", ">" được sử dụng để phân biệt các n-gram với các từ hoàn chỉnh. Khi huấn luyện xong, vector nhúng từ của từ "đồng" sẽ là tổng các vector nhúng từ của ["<đồng>", "<đồ", "đồn", "ồng", "ng>"] nhân với vector của từ "đồng". Điều này cho phép FastText tạo ra vector nhúng từ cho các từ chưa xuất hiện trong quá trình huấn luyện bằng cách kết hợp các vector n-gram có sẵn.
e) GloVe
GloVe (Global Vectors) là thuật toán học phép nhúng từ do đại học Stanford công bố vào năm 2014. Ý tưởng chính của GloVe là từ việc quan sát rằng những từ có cùng ý nghĩa hoặc mối quan hệ gần gũi sẽ có xác suất xuất hiện đồng thời cao hơn.
GloVe xây dựng một ma trận xuất hiện đồng thời X dựa trên quan sát này. Từ ma trận X, nó tính toán ma trận log xác suất xuất hiện đồng thời P. Sau đó, GloVe sử dụng hai ma trận word_vector[V x N] và context_vector[N x V] để tối ưu hóa tích vô hướng của chúng sao cho bằng ma trận P. Cuối cùng, ma trận word_vector là ma trận nhúng từ được tìm thấy.
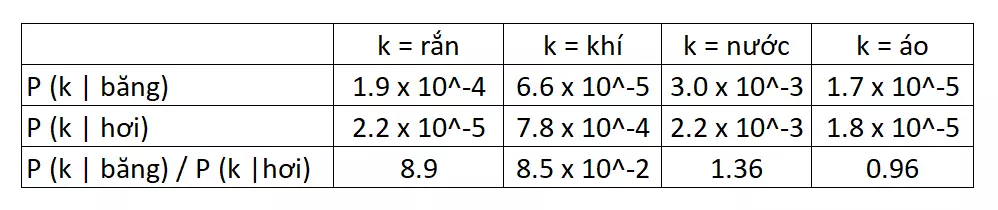
Đây là một hình minh họa cho ma trận xuất hiện đồng thời và ma trận log xác suất xuất hiện đồng thời:
Ma trận xuất hiện đồng thời:
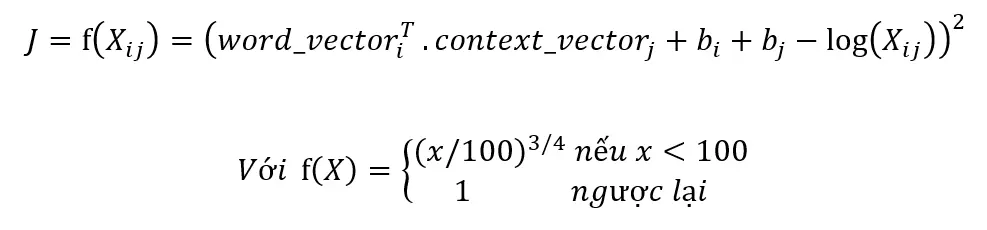
Ma trận log xác suất xuất hiện đồng thời:
Qua phần 2 này, chúng ta đã được giới thiệu đến 3 trong số các phương pháp nhúng từ phổ biến nhất hiện nay. Những phương pháp này đã được cộng đồng học máy sử dụng trong nhiều năm và đã tạo ra nhiều mô hình huấn luyện cho nhiều ngôn ngữ và thư viện khác nhau. Đối với các bài toán học máy đơn giản và nhỏ, hoặc làm thước đo cơ bản trước khi áp dụng các phương pháp nhúng từ cao cấp hơn, các phương pháp này là sự lựa chọn tốt.
Trong phần tiếp theo, chúng ta sẽ tổng kết vài phương pháp nhúng từ mới xuất hiện trong 2 năm gần đây như ELMo, BERT, XLNet và ERNIE. Những phương pháp này đòi hỏi tập dữ liệu lớn và nguồn lực tính toán mạnh mẽ, nhưng mang lại hiệu suất cao và đã vượt qua con người trong một số tác vụ như Trả lời câu hỏi (question answering SQuAD 2.0) và Đánh giá hiểu biết ngôn ngữ tổng quát (General Language Understanding Evaluation - GLUE).










