

Image: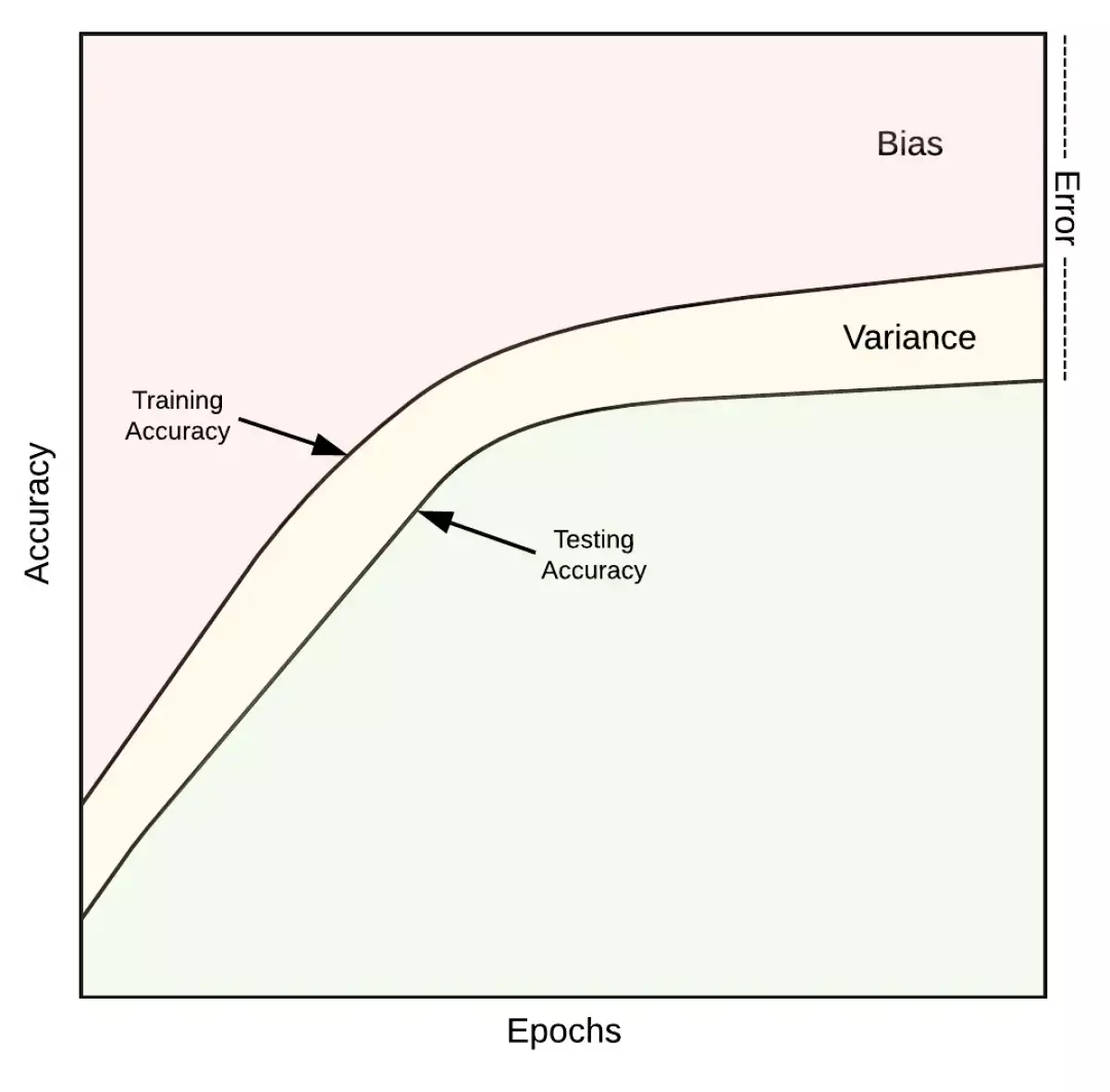 Biểu đồ bias - variance. Nguồn towardsdatascience.com
Biểu đồ bias - variance. Nguồn towardsdatascience.com
Việc huấn luyện mô hình máy học có thể gây khó khăn nếu bạn không hiểu những gì bạn đang làm. Trong hầu hết các trường hợp, các mô hình học máy là những "hộp đen", chúng ta chỉ có thể nhìn thấy dữ liệu đầu vào và độ chính xác mà mô hình trả về. Chúng ta không biết nó hoạt động như thế nào bên trong. Việc hiểu lý do tại sao mô hình cho ra kết quả kém cỏi là chìa khóa để cải thiện nó.
Bias và Variance
Để tăng độ chính xác của mô hình, chúng ta cần hiểu hai khái niệm quan trọng: bias và variance.
Bias mô tả khả năng học của mô hình. Giá trị bias lớn đồng nghĩa với việc mô hình cần học nhiều hơn từ tập huấn luyện. Nếu mô hình có độ chính xác 90% trên tập huấn luyện, điều đó có nghĩa là bạn có 10% bias. Bias có thể chia thành hai nhóm: bias có thể tránh được và bias không thể tránh được.
Unavoidable bias là giới hạn tối đa của mô hình. Ví dụ, trong một số bài toán như dự đoán giá chứng khoán, không thể dự đoán chính xác 100%. Vì vậy, mô hình của chúng ta vẫn sẽ cho ra kết quả sai trong tình huống lý tưởng nhất. Nếu chúng ta quyết định chấp nhận độ sai tối thiểu là 4%, chúng ta có 4% unavoidable bias.
Avoidable bias xảy ra khi mô hình chưa đạt đến độ tổng quát tối ưu. Chúng ta có thể giảm unavoidable bias bằng cách:
Tăng kích thước mô hình
Việc tăng kích thước mô hình giúp mô hình học được nhiều mối quan hệ phức tạp hơn. Chúng ta có thể thêm các layer hoặc node vào mô hình để tăng kích thước mô hình.
Giảm regularization
Việc giảm regularization giúp mô hình tăng độ chính xác trên tập huấn luyện. Tuy nhiên, chúng ta cần lưu ý không giảm quá mức, vì điều này sẽ làm tăng variance.
Thay đổi kiến trúc mô hình
Thay đổi kiến trúc mô hình cũng có thể giúp chúng ta đạt được độ chính xác cao hơn. Chúng ta có thể thay đổi activation function, loại mô hình, các tham số và thuật toán tối ưu để cải thiện mô hình.
Thêm đặc trưng
Thêm đặc trưng giúp cung cấp nhiều thông tin hơn cho mô hình. Chúng ta có thể thực hiện việc này thông qua kỹ thuật feature engineering.
Variance mô tả mức độ tổng quát hóa của mô hình đối với dữ liệu mà nó chưa được huấn luyện. Và định nghĩa của nó là phần sai lệch giữa độ chính xác trên tập huấn luyện và độ chính xác trên tập kiểm tra.
Để giảm variance, chúng ta có thể:
Thêm nhiều dữ liệu
Thêm dữ liệu là cách đơn giản nhất và hiệu quả nhất để tăng độ chính xác của mô hình khi mô hình bị high variance.
Giảm kích thước mô hình
Giảm kích thước mô hình giúp chúng ta giảm overfitting trên tập huấn luyện. Mục tiêu của việc này là giảm liên kết giữa các pattern dữ liệu. Tuy nhiên, chúng ta thường sử dụng tăng regularization hơn là giảm kích thước mô hình để giảm variance.
Tăng regularization
Việc tăng regularization giúp mô hình chống overfitting, giảm variance và tăng bias. Một số phương pháp regularization phổ biến là dropout và BatchNorm.
Lựa chọn đặc trưng (feature selection)
Giảm chiều dữ liệu bằng cách loại bỏ các đặc trưng thừa giúp giảm nhiễu và giảm variance. Chúng ta có thể sử dụng PCA để lọc ra các đặc trưng quan trọng.
Sau tất cả, chúng ta đã được tổng hợp một bức tranh tổng quát về các lỗi mà chúng ta đang gặp và cách giảm chúng. Hãy tăng cường kiến thức và ứng dụng những nguyên tắc này để tạo ra các mô hình máy học chính xác hơn.
Image: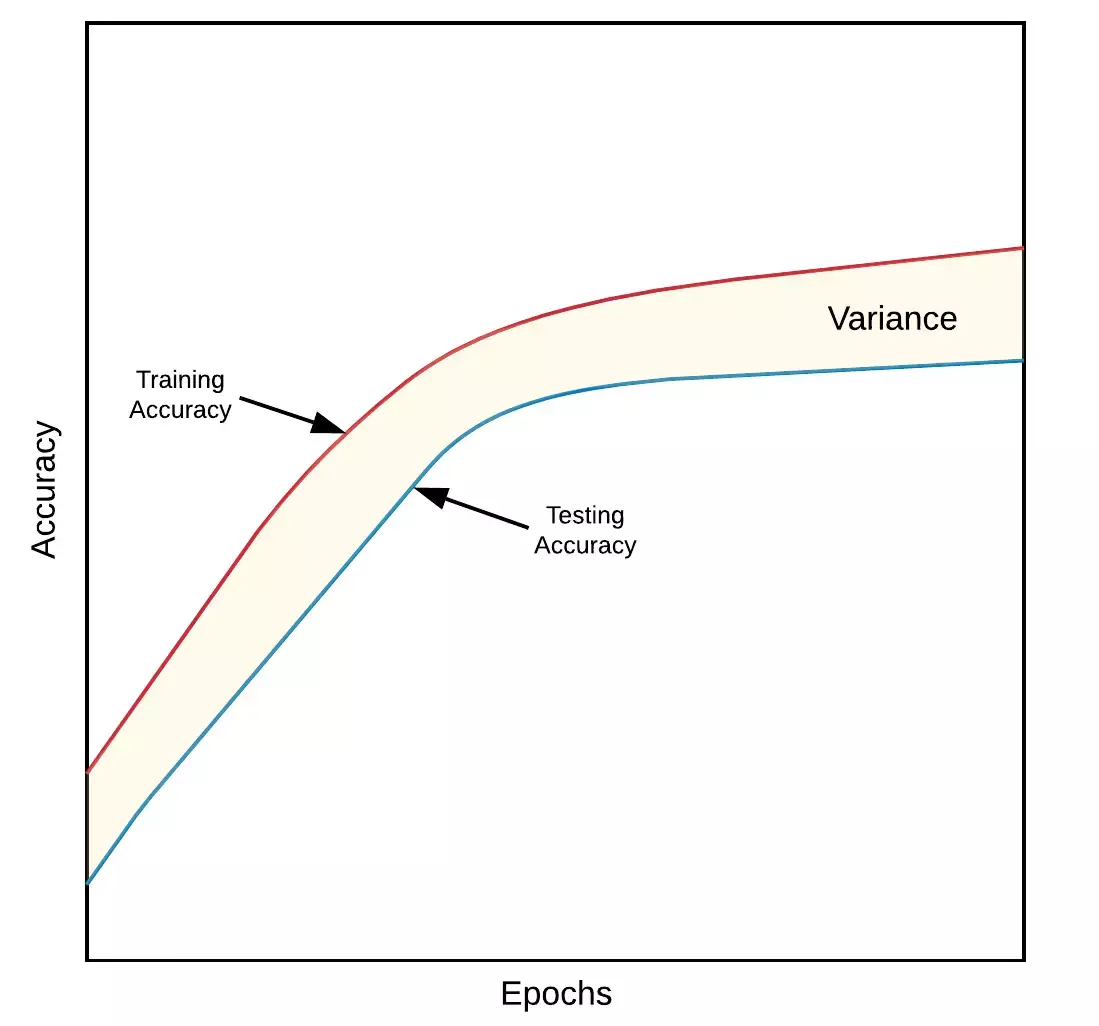 Biểu đồ variance. Nguồn towardsdatascience.com
Biểu đồ variance. Nguồn towardsdatascience.com
Image: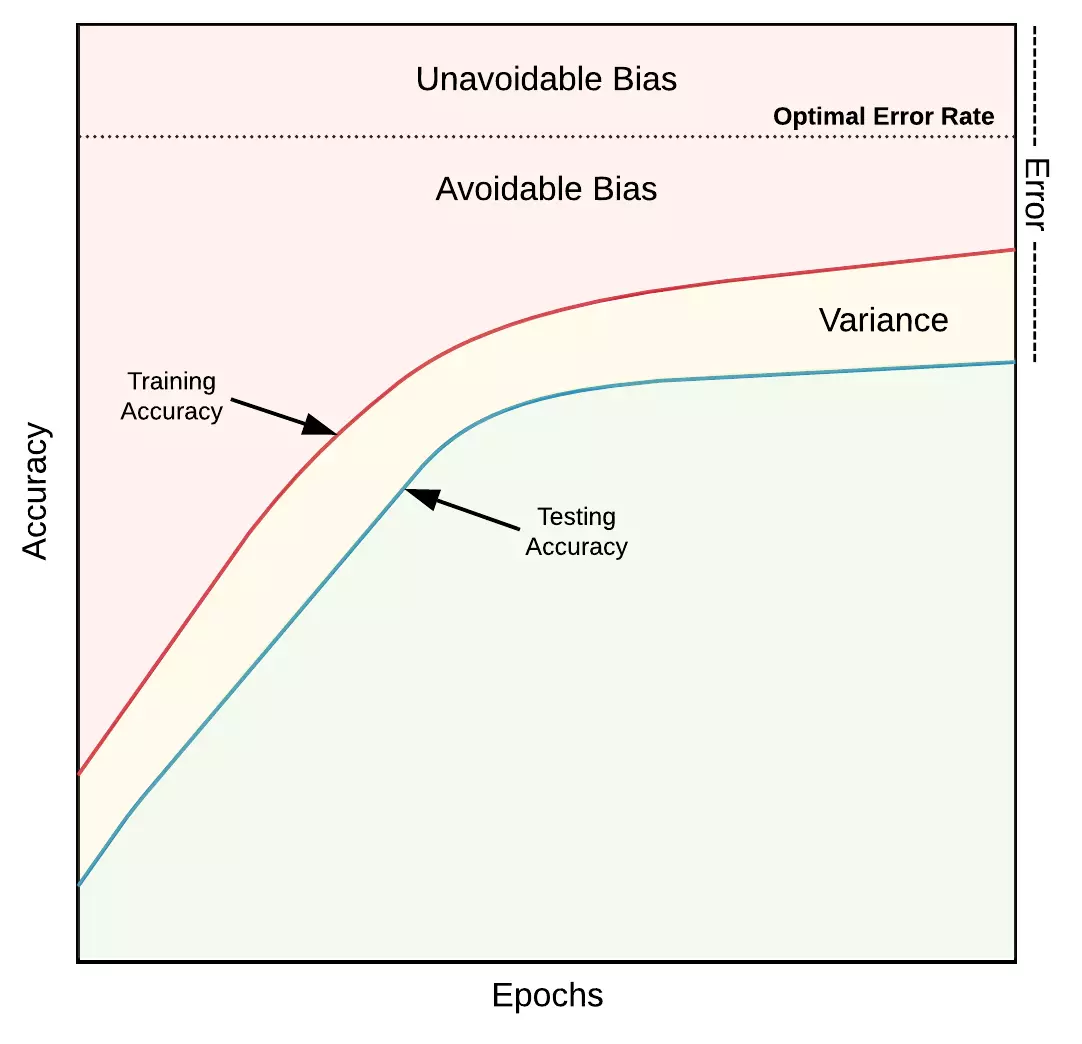 Sự đánh đổi giữa bias và varian. Nguồn towardsdatascience.com
Sự đánh đổi giữa bias và varian. Nguồn towardsdatascience.com
Cảm ơn bạn đã quan tâm và đọc bài viết này. Hẹn gặp bạn ở những bài viết tiếp theo.
Bài viết được lược dịch từ đây.











