

Word Embedding - Nhúng từ là một trong những kĩ thuật phổ biến nhất được sử dụng trong xử lí ngôn ngữ tự nhiên (NLP). Kỹ thuật này giúp máy tính hiểu và xử lí ngôn ngữ một cách tự nhiên, và đóng vai trò quan trọng trong việc phát triển các mô hình học sâu tiên tiến trong lĩnh vực NLP. Trong bài viết này, chúng ta sẽ tìm hiểu về word embedding và áp dụng một vài mô hình học sâu nổi tiếng để thực hiện kỹ thuật này.
Word Embedding là gì?
Word Embedding, hay còn gọi là nhúng từ, là kỹ thuật biểu diễn từ dưới dạng các vector số học liên tục. Điểm khác biệt của word embedding so với kỹ thuật biểu diễn từ truyền thống (one-hot encoding) đó là các vector nhúng từ này có thể học được thông qua quá trình huấn luyện. Bằng cách sử dụng các vector nhúng từ, chúng ta có thể biểu diễn sự tương quan giữa các từ trong ngôn ngữ tự nhiên.
Ví dụ, trong câu "Tôi thích ăn táo và chuối", khi đổi chỗ từ "táo" và "chuối", ý nghĩa của câu không thay đổi. Điều này cho thấy sự tương quan giữa hai từ này trong mặt ngữ nghĩa và cả ngữ pháp (cả hai đều là danh từ). Tương tự, từ "chuối" và "màu vàng" cũng có sự tương quan về mặt ngữ nghĩa (vì chuối thường có màu vàng). Có nhiều thuật toán khác nhau để xây dựng các vector nhúng từ, nhưng trong bài viết này, chúng ta chỉ tập trung vào hai phương pháp phổ biến là Feedforward Neural Net Language Model (NNLM) và Word2Vec.
Feedforward Neural Net Language Model (NNLM)
NNLM là một mô hình sử dụng mạng nơ-ron nhằm dự đoán từ tiếp theo dựa trên các từ bối cảnh trước đó. Kiến trúc mạng của NNLM bao gồm các lớp nhúng từ (embedding layer), các lớp ẩn (hidden layers) và lớp softmax. Trong quá trình huấn luyện, mạng sẽ nhận đầu vào là một số lượng từ bối cảnh và dự đoán từ tiếp theo có xác suất cao nhất.
Để hiểu cách hoạt động của mô hình NNLM, chúng ta sẽ xây dựng một mạng NNLM đơn giản bằng Pytorch. Trong mạng này, từ sau khi được nhúng sẽ được ghép lại thành một vector đầu vào và đi qua các lớp ẩn, sau đó được đưa vào hàm softmax để tạo ra phân phối xác suất cho các từ trong từ điển.
Word2Vec
Word2Vec là một mô hình word embedding phổ biến được giới thiệu bởi Mikolov vào năm 2013. Mô hình này sử dụng hai kiến trúc chính là Continuous Bag-Of-Words (CBOW) và Skip-gram để học ma trận nhúng từ.
Trong CBOW, mô hình sẽ dự đoán từ mục tiêu dựa trên các từ bối cảnh xung quanh nó. Ví dụ, trong câu "Tôi thích ăn táo và chuối", mô hình CBOW sẽ sử dụng các từ "táo" và "chuối" để dự đoán từ "thích".
Ngược lại, trong Skip-gram, mô hình sẽ dự đoán các từ bối cảnh xung quanh một từ mục tiêu. Sử dụng lại ví dụ trên, mô hình Skip-gram sẽ sử dụng từ "thích" để dự đoán các từ "táo", "ăn", "và", "chuối".
Điểm đặc biệt của Word2Vec đó là nó giảm chi phí tính toán so với NNLM. Điều này được thực hiện bằng cách sử dụng negative sampling và các kỹ thuật khác để tối ưu tốc độ huấn luyện và độ chính xác của mô hình.
Kết luận
Word embedding là một kỹ thuật quan trọng trong xử lí ngôn ngữ tự nhiên. Nhờ vào các vector nhúng từ, máy tính có khả năng hiểu và xử lí ngôn ngữ một cách tự nhiên. Trong bài viết này, chúng ta đã tìm hiểu về word embedding và các mô hình học sâu như NNLM và Word2Vec. Hy vọng rằng những kiến thức này sẽ giúp bạn hiểu rõ hơn về công nghệ này và áp dụng nó vào các dự án NLP của mình.
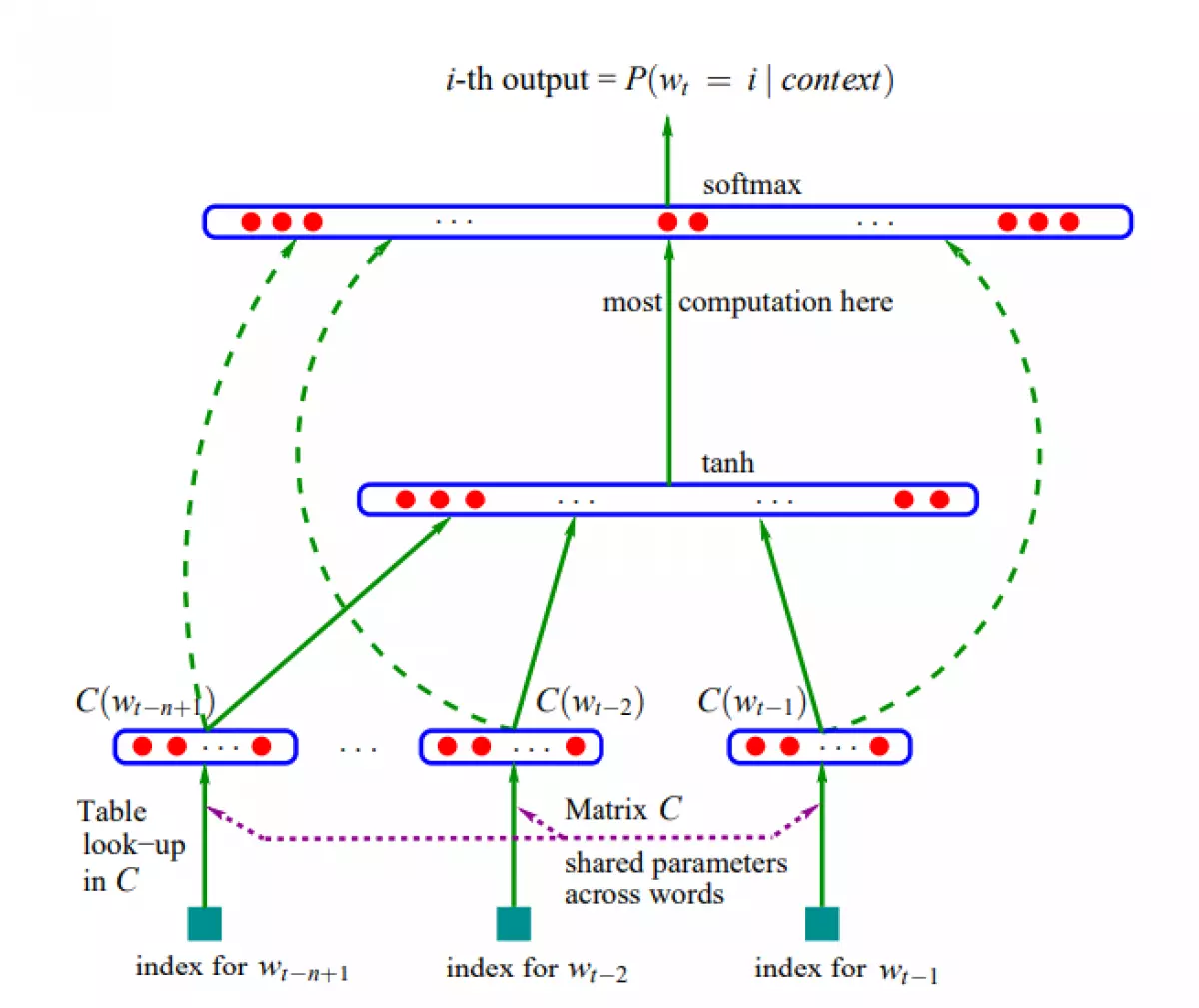 Caption: Một ví dụ về ma trận nhúng từ được xây dựng trong quá trình huấn luyện mạng NNLM.
Caption: Một ví dụ về ma trận nhúng từ được xây dựng trong quá trình huấn luyện mạng NNLM.
Chú ý: Trong phần implement của mô hình NNLM và Word2Vec, mình sẽ để ở Colab Notebook tại đây.










