Đôi khi, trong một ứng dụng, chúng ta cần sắp xếp hoặc truy xuất dữ liệu mà không có thứ tự. Để xử lý và sử dụng dữ liệu một cách hiệu quả, chúng ta phải sắp xếp lại nó. Trong thời gian qua, các nhà khoa học máy tính đã phát triển nhiều thuật toán sắp xếp để tổ chức dữ liệu.
Các thuật toán sắp xếp phổ biến
Trong bài viết này, chúng ta sẽ tìm hiểu về các thuật toán sắp xếp phổ biến, hiểu cách chúng hoạt động và cách thực hiện chúng bằng Python. Chúng ta cũng sẽ so sánh tốc độ của các thuật toán để xem thuật toán nào nhanh hơn trong việc sắp xếp các phần tử trong một danh sách. Để đơn giản, chúng tôi sẽ triển khai các thuật toán sao cho danh sách các số được sắp xếp theo thứ tự tăng dần. Các thuật toán sắp xếp phổ biến mà chúng ta sẽ xem xét bao gồm:
- Bubble Sort
- Selection Sort
- Insertion Sort
- Merge Sort
- Heap Sort
- Quick Sort
- Sorting in Python
Bubble Sort
Thuật toán Bubble Sort này lặp lại qua một danh sách, so sánh các phần tử theo cặp và hoán đổi chúng cho đến khi các phần tử lớn hơn "nổi bong bóng" đến cuối danh sách và các phần tử nhỏ hơn nằm ở "dưới cùng".
Giải thích: Chúng ta bắt đầu bằng cách so sánh hai phần tử đầu tiên trong danh sách. Nếu phần tử đầu tiên lớn hơn phần tử thứ hai, chúng ta hoán đổi chúng. Nếu chúng đã được sắp xếp, chúng ta giữ nguyên. Sau đó, chúng ta tiếp tục với cặp phần tử tiếp theo, so sánh giá trị của chúng và hoán đổi nếu cần thiết. Quá trình này tiếp tục cho đến cặp cuối cùng trong danh sách.
Khi chúng ta đến cuối danh sách, thuật toán lặp lại quá trình này cho mọi phần tử. Mặc dù điều này không hiệu quả, vì chúng ta chỉ cần hoán đổi một phần tử duy nhất, nhưng chúng ta vẫn lặp lại qua danh sách lần lượt, nhiều lần với "lũy treo". Để tối ưu hóa thuật toán, chúng ta cần dừng nó khi đã sắp xếp xong.
Làm thế nào chúng ta biết rằng chúng ta đã hoàn tất sắp xếp? Nếu các phần tử theo thứ tự, chúng ta sẽ không cần hoán đổi các phần tử. Vì vậy, mỗi khi chúng ta hoán đổi giá trị, chúng ta đặt flag thành True để lặp lại quá trình sắp xếp. Nếu không có hoán đổi xảy ra, flag vẫn là False và thuật toán sẽ dừng lại.
Đây là mã nguồn Python để triển khai Bubble Sort:
def bubble_sort(nums):
# We set swapped to True so the loop looks runs at least once
swapped = True
while swapped:
swapped = False
for i in range(len(nums) - 1):
if nums[i] > nums[i + 1]:
# Swap the elements
nums[i], nums[i + 1] = nums[i + 1], nums[i]
# Set the flag to True so we'll loop again
swapped = TrueĐộ phức tạp thời gian của Bubble Sort
Trong trường hợp xấu nhất (khi danh sách được sắp xếp ngược), thuật toán này sẽ phải hoán đổi tất cả các phần tử của mảng. Cờ swapped của chúng tôi sẽ được đặt thành True trên mỗi lần lặp. Do đó, nếu chúng ta có n phần tử trong danh sách của mình, chúng ta sẽ có n lần lặp cho mỗi mục - do đó độ phức tạp thời gian của Bubble Sort là O(n^2).
Selection Sort
Thuật toán Selection Sort này chia mảng thành hai phần: các phần tử đã được sắp xếp và các phần tử chưa được sắp xếp. Nó lặp lại qua phân đoạn chưa được sắp xếp và chọn phần tử nhỏ nhất. Phần tử nhỏ nhất được chọn được đặt vào phân đoạn đã được sắp xếp.
Giải thích: Trong thực tế, chúng ta không cần tạo một danh sách mới cho các phần tử đã được sắp xếp, những gì chúng ta làm là xem phần bên trái của danh sách là phân đoạn đã được sắp xếp. Sau đó chúng ta tìm kiếm phần tử nhỏ nhất trong toàn bộ danh sách và hoán đổi nó với phần tử đầu tiên.
Đây là mã nguồn Python để triển khai Selection Sort:
def selection_sort(nums):
# This value of i corresponds to how many values were sorted
for i in range(len(nums)):
# We assume that the first item of the unsorted segment is the smallest
lowest_value_index = i
# This loop iterates over the unsorted items
for j in range(i + 1, len(nums)):
if nums[j] < nums[lowest_value_index]:
lowest_value_index = j
# Swap values of the lowest unsorted element with the first unsorted
# element
nums[i], nums[lowest_value_index] = nums[lowest_value_index], nums[i]Độ phức tạp thời gian của Selection Sort
Chúng tôi có thể dễ dàng có được độ phức tạp thời gian bằng cách xem xét các vòng lặp trong thuật toán Selection Sort. Đối với một danh sách có n phần tử, vòng lặp bên ngoài lặp lại n lần. Vòng lặp bên trong lặp lại (n-1) lần khi i bằng 1, sau đó (n-2) lần khi i bằng 2 và tiếp tục như vậy.
Số lượng so sánh là (n - 1) + (n - 2) + ... + 1, điều này mang lại cho Selection Sort độ phức tạp thời gian là O(n^2).
Insertion Sort
Thuật toán Insertion Sort này cũng chia mảng thành hai phần: các phần tử đã được sắp xếp và các phần tử chưa được sắp xếp. Nó lặp lại qua phân đoạn chưa được sắp xếp và chèn phần tử đang xem vào vị trí chính xác trong danh sách đã được sắp xếp.
Giải thích: Chúng ta bắt đầu bằng cách chọn phần tử thứ hai trong danh sách (nếu danh sách chỉ có một phần tử, thuật toán đã được hoàn thành). Đồng thời, chúng ta lưu trữ một tham chiếu của chỉ mục phần tử trước đó. Chúng ta so sánh phần tử này với các phần tử trong danh sách đã được sắp xếp và di chuyển các phần tử lớn hơn sang bên phải cho đến khi chúng ta gặp một phần tử nhỏ hơn hoặc đến cuối danh sách đã được sắp xếp. Sau đó, chúng ta chèn phần tử đang xem vào vị trí chính xác trong danh sách đã được sắp xếp.
Đây là mã nguồn Python để triển khai Insertion Sort:
def insertion_sort(nums):
# Start on the second element as we assume the first element is sorted
for i in range(1, len(nums)):
item_to_insert = nums[i]
# And keep a reference of the index of the previous element
j = i - 1
# Move all items of the sorted segment forward if they are larger than
# the item to insert
while j >= 0 and nums[j] > item_to_insert:
nums[j + 1] = nums[j]
j -= 1
# Insert the item
nums[j + 1] = item_to_insertĐộ phức tạp thời gian của Insertion Sort
Trong trường hợp xấu nhất, một mảng sẽ được sắp xếp theo thứ tự ngược lại. Vòng lặp for bên ngoài trong hàm Sắp xếp chèn sẽ lặp lại n-1 lần.
Trong trường hợp xấu nhất, vòng lặp for bên trong sẽ hoán đổi một lần, sau đó hai lần và cứ thế tiếp tục. Số lượng giao dịch hoán đổi sau đó sẽ là 1 + 2 + ... + (n - 3) + (n - 2) + (n - 1), điều này mang lại cho Insertion Sort độ phức tạp thời gian là O(n^2).
Merge Sort
Thuật toán Merge Sort này phân chia danh sách thành hai phần: các phần tử đã được sắp xếp và các phần tử chưa được sắp xếp. Nó lặp lại quá trình này cho đến khi chúng ta có danh sách đã sắp xếp với tất cả phần tử của danh sách ban đầu chưa được sắp xếp.
Giải thích: Thuật toán Merge Sort phân chia danh sách thành hai nửa và tiếp tục chia từng nửa cho đến khi chúng ta chỉ có một số phần tử. Sau đó, chúng ta trộn các phần tử đã sắp xếp lại với nhau, sắp xếp chúng trong quá trình.
Đây là mã nguồn Python để triển khai Merge Sort:
def merge(left_list, right_list):
sorted_list = []
left_list_index = right_list_index = 0
# We use the list lengths often, so its handy to make variables
left_list_length, right_list_length = len(left_list), len(right_list)
for _ in range(left_list_length + right_list_length):
if left_list_index < left_list_length and right_list_index < right_list_length:
# We check which value from the start of each list is smaller
# If the item at the beginning of the left list is smaller, add it
# to the sorted list
if left_list[left_list_index] <= right_list[right_list_index]:
sorted_list.append(left_list[left_list_index])
left_list_index += 1
# If the item at the beginning of the right list is smaller, add it
# to the sorted list
else:
sorted_list.append(right_list[right_list_index])
right_list_index += 1
# If we've reached the end of the of the left list, add the elements
# from the right list
elif left_list_index == left_list_length:
sorted_list.append(right_list[right_list_index])
right_list_index += 1
# If we've reached the end of the of the right list, add the elements
# from the left list
elif right_list_index == right_list_length:
sorted_list.append(left_list[left_list_index])
left_list_index += 1
return sorted_list
def merge_sort(nums):
# If the list is a single element, return it
if len(nums) <= 1:
return nums
# Use floor division to get midpoint, indices must be integers
mid = len(nums) // 2
# Sort and merge each half
left_list = merge_sort(nums[:mid])
right_list = merge_sort(nums[mid:])
# Merge the sorted lists into a new one
return merge(left_list, right_list)Độ phức tạp thời gian của Merge Sort
Trước tiên, hãy xem xét độ phức tạp thời gian của hàm merge. Trong trường hợp xấu nhất, phần tử lớn nhất không bao giờ là phần tử gốc, điều này gây ra một lệnh gọi đệ quy để merge. Mặc dù các cuộc gọi đệ quy có vẻ tốn kém, hãy nhớ rằng chúng tôi làm việc với cây nhị phân.
Hãy tưởng tượng một cây nhị phân có 3 phần tử, nó có độ sâu là 2. Bây giờ hãy tưởng tượng một cây nhị phân có 7 phần tử, nó có độ sâu là 3. Cây tăng theo hàm logarithm của n. Hàm mergeify đi qua cây đó trong thời gian O(log(n)).
Hàm merge_sort lặp lại qua mảng n lần. Do đó, độ phức tạp thời gian tổng thể của thuật toán Merge Sort là O(nlog(n)).
Heap Sort
Thuật toán Heap Sort này phân chia danh sách thành hai phần: các phần tử đã được sắp xếp và các phần tử chưa được sắp xếp. Nó chuyển đổi phân đoạn chưa được sắp xếp của danh sách thành cấu trúc dữ liệu Heap, để chúng ta có thể xác định hiệu quả phần tử lớn nhất.
Giải thích: Chúng ta bắt đầu bằng cách chuyển danh sách thành Max Heap - một cây nhị phân trong đó phần tử lớn nhất là nút gốc. Sau đó chúng ta đặt phần tử lớn nhất này vào cuối danh sách. Sau đó, chúng ta xây dựng lại Heap Max của chúng ta với một giá trị nhỏ hơn, đặt giá trị lớn nhất mới trước mục cuối cùng của danh sách. Chúng ta lặp lại quá trình xây dựng Heap này cho đến khi tất cả các nút được loại bỏ.
Đây là mã nguồn Python để triển khai Heap Sort:
def heapify(nums, heap_size, root_index):
# Assume the index of the largest element is the root index
largest = root_index
left_child = (2 * root_index) + 1
right_child = (2 * root_index) + 2
# If the left child of the root is a valid index, and the element is greater
# than the current largest element, then update the largest element
if left_child < heap_size and nums[left_child] > nums[largest]:
largest = left_child
# Do the same for the right child of the root
if right_child < heap_size and nums[right_child] > nums[largest]:
largest = right_child
# If the largest element is no longer the root element, swap them
if largest != root_index:
nums[root_index], nums[largest] = nums[largest], nums[root_index]
# Heapify the new root element to ensure it's the largest
heapify(nums, heap_size, largest)
def heap_sort(nums):
n = len(nums)
# Create a Max Heap from the list
# The 2nd argument of range means we stop at the element before -1 i.e.
# the first element of the list.
# The 3rd argument of range means we iterate backwards, reducing the count
# of i by 1
for i in range(n, -1, -1):
heapify(nums, n, i)
# Move the root of the max heap to the end of
for i in range(n - 1, 0, -1):
nums[i], nums[0] = nums[0], nums[i]
heapify(nums, i, 0)Độ phức tạp thời gian của Heap Sort
Trước tiên, hãy xem xét độ phức tạp thời gian của hàm heapify. Trường hợp xấu nhất xảy ra khi phần tử lớn nhất không bao giờ là phần tử gốc. Điều này sẽ tạo ra các phân vùng có kích thước n-1, gây ra các cuộc gọi đệ quy n-1 lần. Điều này dẫn chúng ta đến độ phức tạp thời gian trong trường hợp xấu nhất của O(n^2).
Mặc dù đây là trường hợp xấu nhất, Heap Sort được sử dụng rất nhiều vì độ phức tạp thời gian trung bình nhanh hơn nhiều. Trong khi hàm heapify sử dụng các vòng lặp lồng nhau trong khi các vòng lặp, nó sẽ so sánh trên tất cả các phần tử của mảng để thực hiện các giao dịch hoán đổi của nó. Như vậy, nó có độ phức tạp thời gian là O(n).
Với một heap tốt, hàm heap_sort sẽ phân vùng mảng thành một nửa, tăng lên logarit theo n. Do đó, độ phức tạp thời gian trung bình của thuật toán Heap Sort là O(nlog(n)).
Quick Sort
Thuật toán Quick Sort là một thuật toán sắp xếp phổ biến, được sử dụng rộng rãi và hiệu quả. Khi định cấu hình chính xác, nó cực kỳ hiệu quả và không yêu cầu sử dụng Heap Sort hoặc Merge Sort.
Giải thích: Quick Sort bắt đầu bằng cách phân đoạn danh sách - chọn một giá trị làm trục cho danh sách sẽ được sắp xếp. Tất cả các phần tử nhỏ hơn trục được di chuyển sang bên trái của nó. Tất cả các phần tử lớn hơn được di chuyển sang bên phải của nó. Vì chúng ta biết rằng trục nằm ở vị trí chính xác, chúng tôi sắp xếp đệ quy phần trước và phần sau của danh sách cho đến khi toàn bộ danh sách đã sắp xếp.
Đây là mã nguồn Python để triển khai Quick Sort:
# There are different ways to do a Quick Sort partition, this implements the
# Hoare partition scheme. Tony Hoare also created the Quick Sort algorithm.
def partition(nums, low, high):
# We select the middle element to be the pivot. Some implementations select
# the first element or the last element. Sometimes the median value becomes
# the pivot, or a random one. There are many more strategies that can be
# chosen or created.
pivot = nums[(low + high) // 2]
i = low - 1
j = high + 1
while True:
i += 1
while nums[i] < pivot:
i += 1
j -= 1
while nums[j] > pivot:
j -= 1
if i >= j:
return j
nums[i], nums[j] = nums[j], nums[i]
def quick_sort(nums):
# Create a helper function that will be called recursively
def _quick_sort(items, low, high):
if low < high:
# This is the index after the pivot, where our lists are split
split_index = partition(items, low, high)
_quick_sort(items, low, split_index)
_quick_sort(items, split_index + 1, high)
_quick_sort(nums, 0, len(nums) - 1)Độ phức tạp thời gian của Quick Sort
Trường hợp xấu nhất xảy ra khi phần tử nhỏ nhất hoặc lớn nhất luôn được chọn làm pivot. Điều này sẽ tạo phân vùng có kích thước n-1, dẫn đến các cuộc gọi đệ quy n-1 lần. Điều này dẫn chúng ta tới tiệm cận trong trường hợp xấu nhất của O(n^2).
Mặc dù đây là trường hợp xấu nhất, Quick Sort được sử dụng rất nhiều vì độ phức tạp thời gian trung bình nhanh hơn nhiều. Trong khi hàm partition sử dụng các vòng lặp để chia các phần tử thành các phần vùng, nó sẽ so sánh trên tất cả các phần tử của list để thực hiện các giao dịch hoán đổi của nó. Như vậy, nó có độ phức tạp thời gian là O(n).
Với một pivot tốt, hàm quick_sort sẽ phân vùng mảng thành nửa, tăng lên logarit theo n. Do đó, độ phức tạp thời gian trung bình của thuật toán Quick Sort là O(nlog(n)).
Sắp xếp trong Python
Mặc dù có ích khi hiểu các thuật toán sắp xếp này, trong hầu hết các dự án Python, bạn thường sẽ sử dụng các hàm sắp xếp có sẵn trong ngôn ngữ. Bạn có thể sắp xếp danh sách của mình bằng cách sử dụng phương thức sort():
apples_eaten_a_day = [2, 1, 1, 3, 1, 2, 2]
apples_eaten_a_day.sort()
print(apples_eaten_a_day) # [1, 1, 1, 2, 2, 2, 3]Hoặc bạn có thể sử dụng hàm sorted() để tạo một danh sách được sắp xếp mới:
apples_eaten_a_day_2 = [2, 1, 1, 3, 1, 2, 2]
sorted_apples = sorted(apples_eaten_a_day_2)
print(sorted_apples) # [1, 1, 1, 2, 2, 2, 3]Cả hai đều sắp xếp theo thứ tự tăng dần. Bạn cũng có thể dễ dàng sắp xếp theo thứ tự giảm dần bằng cách đặt tham số đảo ngược thành True:
# Reverse sort the list in-place
apples_eaten_a_day.sort(reverse=True)
print(apples_eaten_a_day) # [3, 2, 2, 2, 1, 1, 1]
# Reverse sort to get a new list
sorted_apples_desc = sorted(apples_eaten_a_day_2, reverse=True)
print(sorted_apples_desc) # [3, 2, 2, 2, 1, 1, 1]Khác với các hàm thuật toán sắp xếp mà chúng tôi đã triển khai, cả hai hàm này có thể sắp xếp danh sách các đối tượng và các lớp. Hàm sort() có thể sắp xếp bất kỳ đối tượng có thể lặp lại nào, bao gồm - danh sách, chuỗi, bộ dữ liệu, từ điển, bộ và trình lặp tùy chỉnh mà bạn có thể tạo. Các hàm sắp xếp này thực hiện thuật toán Tim Sort, một thuật toán được lấy cảm hứng từ Merge Sort và Insertion Sort.
Để có ý tưởng về hiệu suất của các thuật toán, chúng tôi tạo ra một danh sách gồm 5000 số từ 0 đến 1000. Sau đó chúng tôi ghi lại thời gian mà mỗi thuật toán hoàn thành. Quá trình này được lặp lại 10 lần để chúng ta có thể thiết lập một mô hình hiệu suất đáng tin cậy hơn.
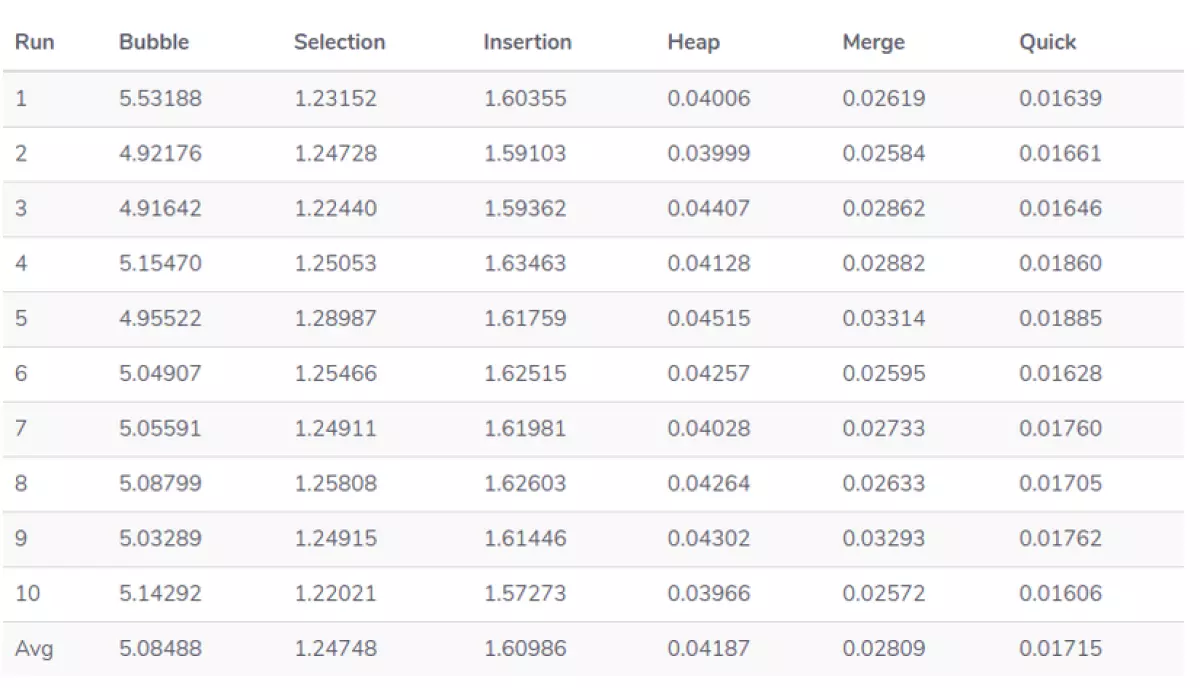
Bạn có thể nhận được các giá trị khác nhau nếu bạn tự thiết lập thử nghiệm của mình, nhưng các mẫu quan sát phải giống hoặc tương tự nhau. Bubble Sort là thuật toán chậm nhất trong tất cả các thuật toán. Mặc dù nó hữu ích như là một giới thiệu về sắp xếp và thuật toán, nó không phù hợp để sử dụng trong thực tế.
Chúng tôi cũng nhận thấy rằng Quick Sort rất nhanh, nhanh gần gấp đôi so với Merge Sort và nó sẽ không cần nhiều không gian để chạy. Hãy nhớ rằng phân vùng của chúng ta dựa trên yếu tố giữa của danh sách, các phân vùng khác nhau có thể có kết quả khác nhau.
Vì Insertion Sort thực hiện so sánh ít hơn nhiều so với Selection Sort, việc triển khai thường nhanh hơn, nhưng trong các lần chạy này, Selection Sort nhanh hơn một chút.
Insertion Sort thực hiện nhiều hoán đổi hơn so với Selection Sort. Nếu các hoán đổi chiếm nhiều thời gian hơn so với so sánh các giá trị, thì kết quả "trái ngược" này sẽ hợp lý. Hãy chú ý đến môi trường khi chọn thuật toán sắp xếp phù hợp nhất cho bạn, vì nó sẽ ảnh hưởng đến hiệu suất.
Nguồn: [https://nanado.edu.vn/sap-xep-trong-python-cung-xem-qua-thuat-toan-sap-xep/]