


Deep Learning đã tạo ra những mô hình tốt nhất để giải quyết nhiều bài toán phức tạp như nhận dạng giọng nói, thị giác máy tính, dịch máy, vv. Tuy nhiên, huấn luyện các mô hình Deep Learning là một thách thức khó khăn vì các mô hình hiện tại có cấu trúc phức tạp và phân bố dữ liệu qua các layer thay đổi. Vì vậy, trong bài viết này, chúng ta sẽ tìm hiểu về tầm quan trọng của việc chuẩn hóa và các phương pháp chuẩn hóa trong Deep Learning để áp dụng phù hợp với bài toán của bạn.
Tầm Quan Trọng của Việc Chuẩn Hóa Dữ Liệu Đầu Vào
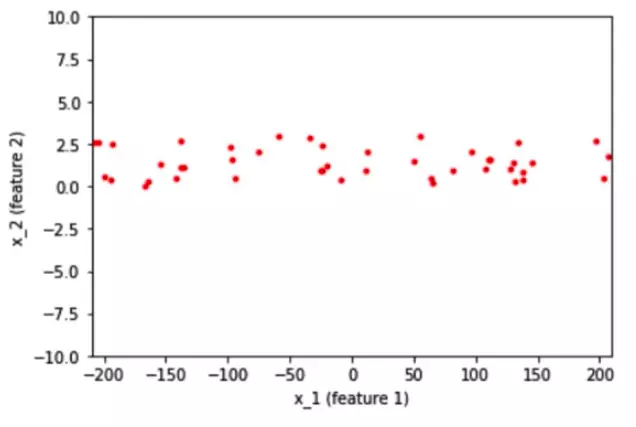
Giả sử bạn có dữ liệu 2D với hai feature x₁ và x₂ đi vào mạng neural. Feature x₁ có giá trị từ -200 đến 200 và feature x₂ có giá trị từ -10 đến 10. Sau khi chuẩn hóa dữ liệu, khoảng giá trị của cả hai feature được đưa về khoảng từ -2 đến 2. Vậy tại sao việc chuẩn hóa lại quan trọng trong trường hợp này?
Trước khi chuẩn hóa dữ liệu đầu vào, các trọng số liên quan đến các feature sẽ khác nhau rất nhiều vì giá trị đầu vào của chúng nằm ở khoảng khác nhau lớn. Điều này dẫn đến một số trọng số lớn và một số trọng số nhỏ. Nếu các trọng số lớn thì ảnh hưởng đến quá trình cập nhật trong quá trình lan truyền ngược. Vì sự phân bố không đồng đều của các trọng số, thuật toán có thể bị dính vào vùng tối ưu cục bộ trước khi tìm đến vị trí tối ưu toàn cục. Do đó, để tránh việc thuật toán mất quá nhiều thời gian dao động khi tối ưu, chúng ta cần chuẩn hóa các feature đầu vào về cùng tỉ lệ và phân phối. Điều này giúp mô hình có thể học nhanh hơn.
Batch Normalization
Batch normalization là một trong những phương pháp chuẩn hóa phổ biến trong Deep Learning. Nó cho phép huấn luyện mạng nơ-ron sâu nhanh hơn và ổn định hơn bằng cách điều chỉnh phân bố đầu vào của các layer trong quá trình huấn luyện. Batch normalization chuẩn hóa các hàm kích hoạt trong mạng theo mini-batch được định nghĩa trước đó. Đối với mỗi feature, batch normalization tính trung bình và phương sai của feature đó trong một mini-batch. Sau đó, nó trừ đi giá trị trung bình và chia cho độ lệch chuẩn của mini-batch đó.
Batch normalization có thể giải quyết một số vấn đề, như:
- Chuẩn hóa dữ liệu mỗi feature giúp mô hình không thiên vị đối với các feature có giá trị cao hơn.
- Giảm vấn đề "Internal Covariate Shift", tức sự biến đổi phân phối của dữ liệu trong quá trình huấn luyện.
- Làm mịn bề mặt hàm loss trở nên mượt mà hơn, dễ tối ưu hóa.
- Giới hạn độ lớn của gradients, giúp tối ưu hóa nhanh chóng.
- Đóng góp một phần nhỏ vào việc Regularization của mô hình.
Tuy nhiên, batch normalization cũng có một số vấn đề, như:
- Ảnh hưởng của kích thước batch. Đối với batch size là 1, phương sai sẽ bằng 0 và batch normalization không hoạt động. Đồng thời, nếu batch nhỏ, nó sẽ tạo ra nhiễu và ảnh hưởng đến quá trình huấn luyện mô hình. Nếu bạn tính toán trên các hệ thống khác nhau, bạn cần đảm bảo batch size giống nhau vì các tham số sẽ khác nhau đối với các hệ thống khác nhau.
- Áp dụng cho mô hình RNN. Trong RNN, các kích hoạt lặp lại của từng time-step sẽ có một câu chuyện khác nhau để kể, điều này yêu cầu chúng ta phải có batch normalization riêng biệt cho từng time-step, làm cho mô hình phức tạp hơn và tốn không gian hơn.
Weight Normalization
Weight normalization là một phương pháp để cải thiện tính tối ưu của trọng số trong mạng neural. Nó tách độ dài của các vector trọng số khỏi hướng của chúng. Weight normalization được định nghĩa như sau:
w = g * v / ||v||
Việc tách các vector trọng số ra khỏi hướng của chúng giúp cải thiện tính tối ưu. Việc thực hiện weight normalization có nhiều lợi ích, bao gồm:
- Cải thiện điều kiện tối ưu và tăng tốc độ hội tụ của thuật toán gradient descent.
- Áp dụng cho các mô hình hồi quy như LSTM và mô hình reinforcement learning.
Layer Normalization
Layer normalization là một phương pháp chuẩn hóa tức thời đầu vào cho mỗi layer trong mạng neural. Phương pháp này không phụ thuộc vào kích thước batch và phụ thuộc vào layer. Layer normalization chuẩn hóa đầu vào trên các layers thay vì chuẩn hóa từng mini-batch.
Layer normalization có một số lợi ích, như:
- Dễ dàng áp dụng cho mô hình RNN bằng cách tính toán thống kê chuẩn hóa riêng biệt cho từng time-step.
- Hiệu quả trong việc ổn định trạng thái ẩn trong các mạng hồi quy.
Instance Normalization
Instance normalization tương tự như layer normalization, tuy nhiên, nó chuẩn hóa qua từng kênh trong từng ví dụ huấn luyện thay vì chuẩn hóa qua các feature đầu vào trong một ví dụ huấn luyện. Instance normalization độc lập với kích thước batch và cho phép áp dụng trong quá trình thử nghiệm mô hình trên toàn bộ loạt ảnh.
Instance normalization có một số lợi ích, như:
- Đơn giản hóa quá trình huấn luyện mô hình.
- Có thể áp dụng trong quá trình thử nghiệm mô hình.
Group Normalization
Group normalization là một giải pháp thay thế cho batch normalization. Phương pháp này chia các kênh thành các nhóm và chuẩn hóa từng nhóm riêng biệt. Group normalization độc lập với kích thước batch và ổn định trong nhiều loại batch size.
Group normalization có một số lợi ích, như:
- Thay thế batch normalization trong một số bài toán Deep Learning.
- Dễ dàng triển khai.
Trong việc hiệu quả của chuẩn hóa, batch normalization vẫn là phương pháp tốt nhất và được sử dụng rộng rãi. Tuy nhiên, khi mô hình của bạn gặp vấn đề khó hội tụ và chạy lâu, bạn có thể thử các phương pháp khác phù hợp với bài toán của bạn. Hy vọng bài viết này đã giúp bạn hiểu về tầm quan trọng của chuẩn hóa và các phương pháp chuẩn hóa trong Deep Learning. Chúc bạn học tập và làm việc hiệu quả!











