

Trong lĩnh vực Machine Learning, việc xác định độ phức tạp của mô hình là một vấn đề quan trọng để tránh over-fitting hoặc underfitting. Trong bài viết này, chúng ta sẽ tìm hiểu về "bias-variance trade-off" - một khái niệm quen thuộc mà mọi người thường dùng để đánh giá độ phức tạp của mô hình.
Bias-Variance Decomposition là gì?
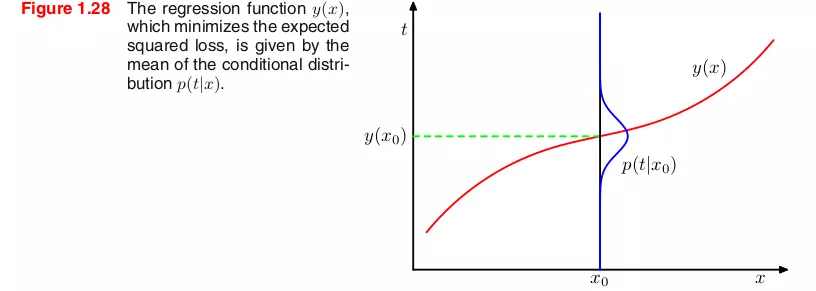
Trong quá trình xác định hàm dự đoán y(x) cho giá trị tại x, chúng ta thường sử dụng hàm loss L(t, y(x)). Lý tưởng nhất là tìm một hàm y(x) sao cho giá trị trung bình của hàm loss E[L] là nhỏ nhất. Để làm được điều này, chúng ta cần tìm hiểu rõ ràng về hai thành phần chính: bias và variance.
Bias đại diện cho sự chênh lệch giữa giá trị trung bình của mô hình dự đoán và giá trị chính xác. Mô hình với bias cao có xu hướng đơn giản quá, không quan tâm nhiều đến dữ liệu huấn luyện và dẫn đến lỗi cao trên cả tập huấn luyện và tập kiểm thử.
Variance, ngược lại, đại diện cho sự biến đổi của giá trị dự đoán cho từng điểm dữ liệu. Mô hình với variance cao tập trung nhiều vào dữ liệu huấn luyện và không tổng quát được trên dữ liệu mới. Điều này dẫn đến kết quả tốt trên tập huấn luyện nhưng kém trên tập kiểm thử.
Ước lượng kỳ vọng loss
Để đánh giá hiệu suất của một thuật toán học, chúng ta có thể chạy thuật toán trên nhiều tập dữ liệu khác nhau. Với mỗi tập dữ liệu, chúng ta thu được một hàm dự đoán y(x;D). Khi lượng dữ liệu không giới hạn, ta có thể dự đoán hàm h(x) với độ chính xác tùy ý và chọn được hàm y(x) tối ưu. Tuy nhiên, trong thực tế, chúng ta chỉ có một tập dữ liệu có số lượng điểm dữ liệu hạn chế. Vì vậy, ta không thể tìm được hàm chính xác h(x).
Khi có nhiều tập dữ liệu D khác nhau, thành phần đầu tiên của biểu thức (2) sẽ biến thành variance + bias^2. Điều này cho thấy, để tối ưu gia trị trung bình của hàm loss, chúng ta cần mô hình có bias thấp và variance càng nhỏ càng tốt. Việc cân bằng giữa bias và variance sẽ giúp tránh tình trạng overfitting hoặc underfitting.
Bias và variance trong Machine Learning
Để hiểu rõ hơn về bias và variance, chúng ta có thể lấy một ví dụ minh hoạ. Trong hình trên, điểm trung tâm là giá trị chính xác mà chúng ta đang cố gắng dự đoán.
Underfitting xảy ra khi mô hình không thể mô tả được các mẫu cơ bản của dữ liệu. Chúng thường có bias cao và variance thấp. Ngược lại, overfitting xảy ra khi mô hình biểu diễn cả dữ liệu nhiễu bên cạnh dữ liệu sạch. Mô hình bị quá phức tạp so với mức độ cần thiết, bị lệ thuộc nhiều vào dữ liệu huấn luyện, thường có bias nhỏ và variance cao.
Kết luận
Trong bài viết này, chúng ta đã tìm hiểu về bias-variance trade-off trong Machine Learning và cách ước lượng kỳ vọng loss. Bias và variance đóng vai trò quan trọng trong việc xác định độ phức tạp của mô hình và cân bằng giữa chúng giúp tránh overfitting và underfitting. Hiểu rõ về bias và variance là yếu tố quan trọng để đánh giá hiệu suất của các mô hình dự đoán trong tương lai.
Nguồn tham khảo: Machine learning and pattern recognition forum Machine learning co ban










