

Trong lĩnh vực khoa học máy tính, bảng băm (Hash Tables) là một cấu trúc dữ liệu được sử dụng để ánh xạ từ khóa (ví dụ như tên của một người) đến giá trị tương ứng (ví dụ như số điện thoại của họ) bằng cách sử dụng hàm băm. Bảng băm có thể được hiểu như một mảng kết hợp. Hàm băm dùng để chuyển đổi từ khóa thành chỉ số trong mảng để lưu trữ các giá trị tìm kiếm.
1. Lý thuyết về bảng băm
Bảng băm là một kỹ thuật được sử dụng để định danh một đối tượng cụ thể trong một nhóm các đối tượng tương tự. Ví dụ, trong trường đại học, mỗi sinh viên được gán một mã sinh viên duy nhất để truy xuất thông tin của sinh viên đó. Trong thư viện, mỗi cuốn sách được gán một mã số riêng để xác định các thông tin của sách đó, chẳng hạn như vị trí chính xác trong thư viện hay thể loại của sách.
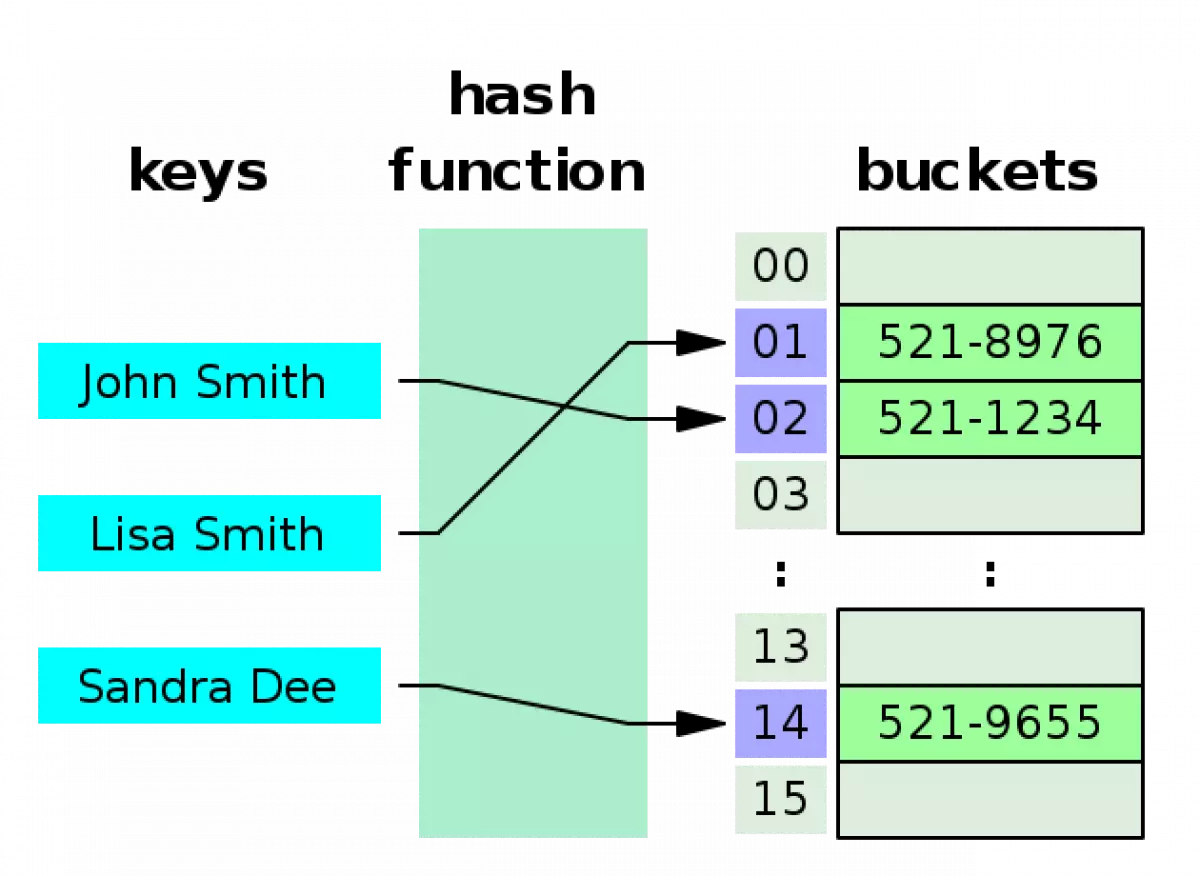 Ảnh minh họa bảng băm
Ảnh minh họa bảng băm
Trong cả hai ví dụ trên, sinh viên và sách đều được "băm" thành mã số duy nhất.
Giả sử bạn có một đối tượng và bạn muốn gán cho nó một khóa để tìm kiếm dễ dàng hơn. Bạn có thể sử dụng một mảng bình thường để làm việc này, với chỉ số mảng là khóa và giá trị tại chỉ số đó là giá trị tương ứng. Tuy nhiên, trong trường hợp khóa có phạm vi lớn và không thể sử dụng chỉ số mảng, bạn cần tới kỹ thuật "băm".
Trong băm, các khóa có giá trị lớn sẽ được chuyển đổi thành giá trị nhỏ hơn bằng cách sử dụng hàm băm. Các giá trị này sau đó được lưu trong một cấu trúc dữ liệu gọi là bảng băm. Ý tưởng của băm là đưa các cặp khóa - giá trị vào một mảng thống nhất, mỗi phần tử trong mảng có một khóa định danh (được tính toán bằng hàm băm). Bằng cách sử dụng khóa định danh đó, chúng ta có thể truy cập trực tiếp đến giá trị tương ứng với độ phức tạp O(1). Thuật toán băm sử dụng khóa băm để tính toán khóa định danh hoặc thêm vào bảng băm.
Việc băm được thực hiện qua 2 bước:
- Một phần tử sẽ được chuyển đổi thành một số nguyên bằng cách sử dụng hàm băm. Phần tử này được sử dụng như một chỉ mục để lưu trữ phần tử gốc và nó sẽ được đưa vào bảng băm.
- Phần tử sẽ được lưu trữ trong bảng băm, và có thể truy cập một cách nhanh chóng bằng khóa băm:
- hash = hashfunc(key)
- index = hash % array_size
Cách trên giúp đưa chỉ số về khoảng [0, array_size-1] bằng cách sử dụng phép chia lấy dư %.
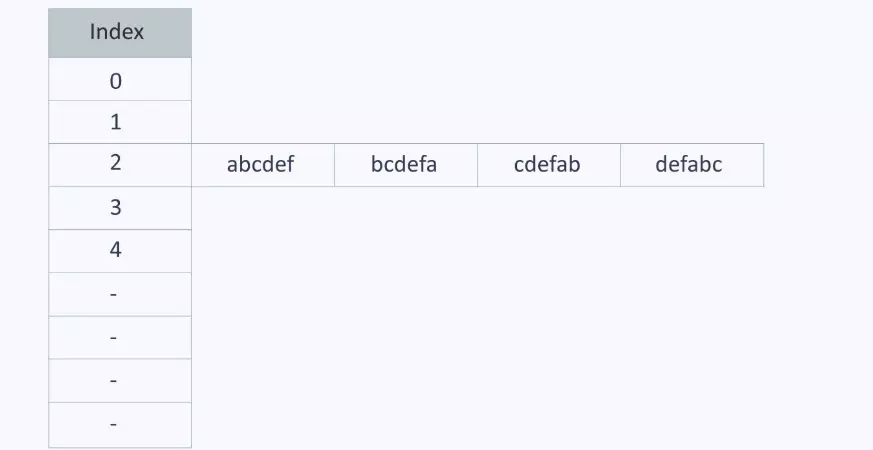 Minh họa cách hàm băm hoạt động
Minh họa cách hàm băm hoạt động
2. Hàm băm
Hàm băm là bất kỳ hàm nào có thể được sử dụng để ánh xạ tập dữ liệu có kích thước tùy ý thành tập dữ liệu có kích thước cố định trong bảng băm. Giá trị trả về của hàm băm được gọi là giá trị băm.
Một hàm băm được coi là tốt nếu nó đáp ứng các yêu cầu sau:
- Dễ tính toán: Hàm băm phải dễ tính toán và không phải là một thuật toán phức tạp.
- Phân bố đồng đều: Hàm băm cần phân phối đồng đều trên bảng băm, tránh tình trạng tập trung các phần tử vào một khu vực.
- Ít va chạm: Va chạm xảy ra khi các cặp phần tử được ánh xạ tới cùng một giá trị băm.
Chú ý: Dù hàm băm có tốt đến đâu, va chạm vẫn có thể xảy ra. Vì vậy, để duy trì hiệu suất của bảng băm, quản lý va chạm là điều quan trọng.
Tại sao cần hàm băm đủ tốt?
Hãy xem xét một ví dụ để dễ hiểu. Giả sử bạn cần lưu trữ các chuỗi sau trong bảng băm: {"abcdef", "bcdefa", "cdefab", "defabc"}.
Để tính toán chỉ mục lưu trữ các chuỗi này, ta có thể sử dụng một hàm băm như sau: chỉ mục của mỗi chuỗi sẽ được tính bằng tổng giá trị ASCII của các ký tự trong chuỗi đó, sau đó lấy phần dư cho 599.
Do 599 là số nguyên tố và nó lớn hơn số lượng phần tử, nó có khả năng tạo ra các chỉ mục khác nhau (giảm va chạm). Giá trị ASCII của các ký tự a, b, c, d, e và f lần lượt là 97, 98, 99, 100, 101 và 102.
Dễ nhận thấy, các chuỗi trên chỉ là các hoán vị của cùng một chuỗi, do đó có cùng một chỉ mục và đều bằng 597 % 5 = 2.
Hàm băm này không tốt vì tất cả các chuỗi có cùng một chỉ mục. Trong trường hợp này, bạn có thể tạo một danh sách tại chỉ mục đó để lưu trữ các chuỗi trong danh sách đó.
Tuy nhiên, việc tìm kiếm một chuỗi cụ thể vẫn phải mất O(n) thời gian. Điều này cho thấy hàm băm này chưa thực sự tốt.
Hãy thử với một hàm băm khác. Chỉ mục của các chuỗi sẽ được tính bằng tổng mã ASCII của từng ký tự theo sau là vị trí của ký tự đó trong chuỗi. Sau đó, chỉ mục được chia lấy dư cho số nguyên tố 2069.
String Hash function Index
abcdef (971 + 982 + 993 + 1004 + 1015 + 1026)%2069 38
bcdefa (981 + 992 + 1003 + 1014 + 1025 + 976)%2069 23
cdefab (991 + 1002 + 1013 + 1024 + 975 + 986)%2069 14
defabc (1001 + 1012 + 1023 + 974 + 985 + 996)%2069 11Lúc này, các chỉ mục của các chuỗi là không trùng lặp (không va chạm).
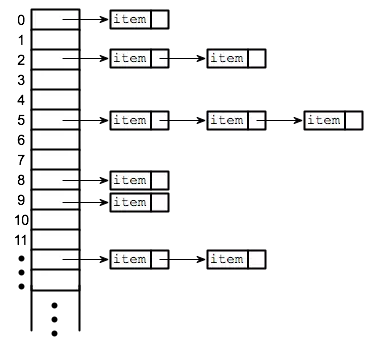
3. Kỹ thuật xử lý va chạm
3.1. Separate chaining (open hashing)
Separate chaining là một kỹ thuật xử lý va chạm phổ biến, thường được triển khai với danh sách liên kết. Để lưu trữ một phần tử trong bảng băm, bạn phải thêm nó vào danh sách liên kết ứng với chỉ mục của nó. Nếu có va chạm xảy ra, các phần tử sẽ cùng nằm trong một danh sách liên kết (xem hình ảnh demo).
Với kỹ thuật này, tốc độ tìm kiếm sẽ là O(1) trong trường hợp tốt nhất và O(n) trong trường hợp tệ nhất khi tất cả các phần tử nằm trong một danh sách liên kết duy nhất. Điều này xảy ra khi chưa đạt được yêu cầu 3 trong tiêu chí hàm băm tốt.
Cách cài đặt bảng băm sử dụng Separate chaining:
Giả sử:
- Hàm băm sẽ trả về một số nguyên trong khoảng từ 0 đến 19.
vector hashTable[20];
int hashTableSize = 20;
// Thêm phần tử vào bảng băm
void insert(string s) {
// Tính chỉ mục bằng hàm băm
int index = hashFunc(s);
// Thêm phần tử vào danh sách liên kết tại chỉ mục đó
hashTable[index].push_back(s);
}
// Tìm kiếm phần tử trong bảng băm
void search(string s) {
// Tính chỉ mục bằng hàm băm
int index = hashFunc(s);
// Tìm kiếm phần tử trong danh sách liên kết tại chỉ mục đó
for (int i = 0; i < hashTable[index].size(); i++) {
if (hashTable[index][i] == s) {
cout << s << " được tìm thấy!" << endl;
return;
}
}
cout << s << " không được tìm thấy!" << endl;
} 3.2. Linear probing (open addressing or closed hashing)
Trong kỹ thuật xử lý va chạm này, chúng ta không sử dụng danh sách liên kết mà chỉ sử dụng mảng của chính bảng băm đó.
Khi thêm phần tử vào bảng băm, nếu chỉ mục đó đã có phần tử, giá trị chỉ mục sẽ được tính toán lại theo phương thức tuần tự. Giả sử chỉ mục là chỉ số của mảng, khi đó, phép tính chỉ mục cho phần tử mới sẽ được tính theo công thức:
index = index % hashTableSize
index = (index + 1) % hashTableSize
index = (index + 2) % hashTableSize
index = (index + 3) % hashTableSizeVà cứ tiếp tục như vậy cho đến khi tìm được chỉ mục chưa được sử dụng. Tất nhiên, không gian chỉ mục phải đảm bảo luôn có chỗ cho phần tử mới.
Ví dụ dưới đây minh họa cho trường hợp bảng băm bị trùng chỉ mục (2) lúc tính chỉ mục lần đầu. Do đó, nó được đẩy lên vị trí trống ở phía sau (3).
Cài đặt bảng băm sử dụng Linear probing:
Giả sử:
- Không có nhiều hơn 20 phần tử trong tập dữ liệu.
- Hàm băm sẽ trả về một số nguyên trong khoảng từ 0 đến 19.
- Tập dữ liệu chỉ chứa các phần tử duy nhất.
string hashTable[21];
int hashTableSize = 21;
// Thêm phần tử vào bảng băm
void insert(string s) {
// Tính chỉ mục bằng hàm băm
int index = hashFunc(s);
// Tìm vị trí trống và nếu chỉ mục vượt quá hashTableSize, quay trở lại vị trí ban đầu
while (hashTable[index] != "")
index = (index + 1) % hashTableSize;
hashTable[index] = s;
}
// Tìm kiếm phần tử trong bảng băm
void search(string s) {
// Tính chỉ mục bằng hàm băm
int index = hashFunc(s);
// Tìm vị trí trống và nếu chỉ mục vượt quá hashTableSize, quay trở lại vị trí ban đầu
while (hashTable[index] != s && hashTable[index] != "")
index = (index + 1) % hashTableSize;
// Kiểm tra phần tử có tồn tại trong bảng băm hay không
if (hashTable[index] == s)
cout << s << " được tìm thấy!" << endl;
else
cout << s << " không được tìm thấy!" << endl;
}3.3. Quadratic Probing
Ý tưởng của kỹ thuật này khá giống với Linear Probing, nhưng cách tính chỉ mục có một chút khác biệt:
index = index % hashTableSize
index = (index + 12) % hashTableSize
index = (index + 22) % hashTableSize
index = (index + 32) % hashTableSizeVà cứ tiếp tục như vậy cho đến khi tìm được chỉ mục chưa được sử dụng.
Cài đặt bảng băm sử dụng Quadratic Probing:
Giả sử:
- Không có nhiều hơn 20 phần tử trong tập dữ liệu.
- Hàm băm sẽ trả về một số nguyên trong khoảng từ 0 đến 19.
- Tập dữ liệu chỉ chứa các phần tử duy nhất.
string hashTable[21];
int hashTableSize = 21;
// Thêm phần tử vào bảng băm
void insert(string s) {
// Tính chỉ mục bằng hàm băm
int index = hashFunc(s);
int h = 1;
// Tìm vị trí trống và nếu chỉ mục vượt quá hashTableSize, quay trở lại vị trí ban đầu
while (hashTable[index] != "") {
index = (index + h*h) % hashTableSize;
h++;
}
hashTable[index] = s;
}
// Tìm kiếm phần tử trong bảng băm
void search(string s) {
// Tính chỉ mục bằng hàm băm
int index = hashFunc(s);
int h = 1;
// Tìm vị trí trống và nếu chỉ mục vượt quá hashTableSize, quay trở lại vị trí ban đầu
while (hashTable[index] != s && hashTable[index] != "") {
index = (index + h*h) % hashTableSize;
h++;
}
// Kiểm tra phần tử có tồn tại trong bảng băm hay không
if (hashTable[index] == s)
cout << s << " được tìm thấy!" << endl;
else
cout << s << " không được tìm thấy!" << endl;
}3.4. Double hashing
Cách tiếp cận này tương tự như hai kỹ thuật trên, nhưng công thức tính chỉ mục sẽ khác một chút khi xảy ra va chạm:
index = (index + 1 * indexH) % hashTableSize;
index = (index + 2 * indexH) % hashTableSize;Và cứ tiếp tục như vậy cho đến khi tìm được chỉ mục chưa được sử dụng.
Cài đặt bảng băm sử dụng Double hashing:
Giả sử:
- Không có nhiều hơn 20 phần tử trong tập dữ liệu.
- Hàm băm sẽ trả về một số nguyên trong khoảng từ 0 đến 19.
- Tập dữ liệu chỉ chứa các phần tử duy nhất.
string hashTable[21];
int hashTableSize = 21;
// Thêm phần tử vào bảng băm
void insert(string s) {
// Tính chỉ mục bằng hàm băm
int index = hashFunc1(s);
int indexH = hashFunc2(s);
// Tìm vị trí trống và nếu chỉ mục vượt quá hashTableSize, quay trở lại vị trí ban đầu
while (hashTable[index] != "") {
index = (index + indexH) % hashTableSize;
}
hashTable[index] = s;
}
// Tìm kiếm phần tử trong bảng băm
void search(string s) {
// Tính chỉ mục bằng hàm băm
int index = hashFunc1(s);
int indexH = hashFunc2(s);
// Tìm vị trí trống và nếu chỉ mục vượt quá hashTableSize, quay trở lại vị trí ban đầu
while (hashTable[index] != s && hashTable[index] != "") {
index = (index + indexH) % hashTableSize;
}
// Kiểm tra phần tử có tồn tại trong bảng băm hay không
if (hashTable[index] == s)
cout << s << " được tìm thấy!" << endl;
else
cout << s << " không được tìm thấy!" << endl;
}4. Ứng dụng của bảng băm
Trong các bài toán thông thường, chúng ta thường sử dụng các cấu trúc dữ liệu có sẵn trong ngôn ngữ lập trình như map, set trong C/C++, Java; Dictionary trong C#, Python. Đó chính là các bảng băm vô cùng hữu ích mà chúng ta thường sử dụng.
Một số ngôn ngữ lập trình như C++ cung cấp cả multi_map và multi_set cho phép lưu trữ các khóa trùng nhau với các giá trị khác nhau. Đó là hai cấu trúc dữ liệu đã được cài đặt kỹ thuật xử lý va chạm.
Với các bài toán đặc thù, bạn sẽ phải tự viết hàm băm và xây dựng cấu trúc dữ liệu bảng băm phù hợp. Dưới đây là một số ứng dụng của bảng băm:
- Associative arrays: Bảng băm thường được sử dụng để triển khai các loại bảng trong bộ nhớ. Chúng được sử dụng để thực hiện các mảng kết hợp (các mảng có chỉ số là các chuỗi tùy ý hoặc các đối tượng phức tạp khác).
- Lập chỉ mục CSDL: Bảng băm cũng có thể được sử dụng để lập chỉ mục dữ liệu trong các cơ sở dữ liệu.
- Caches: Bảng băm được sử dụng để triển khai các cơ chế cache, nhằm tăng tốc độ truy cập dữ liệu.
- Biểu diễn các đối tượng: Một số ngôn ngữ như Perl, Python, JavaScript và Ruby sử dụng bảng băm để triển khai các đối tượng.
- Hàm băm được sử dụng trong các thuật toán khác nhau để tăng tốc độ tính toán.
5. Bài tập thực hành
Dưới đây là một số liên kết chứa bài tập thực hành dành cho bạn:










