Trong thế giới kỹ thuật số ngày nay, việc thu thập dữ liệu từ các trang web khác nhau đã trở thành một kỹ năng quan trọng. Với việc sử dụng Python và kỹ thuật Web Scraping, bạn có thể tiết kiệm thời gian và công sức trong việc thu thập dữ liệu từ nhiều nguồn khác nhau.
Xem qua hướng dẫn về Web-Scraping với Python của chúng tôi
Web Scraping liên quan đến việc trích xuất dữ liệu từ web. Một Web Scraper là một công cụ thực hiện công việc Web Scraping. Python là một trong những ngôn ngữ kịch bản dễ nhất hiện có và có nhiều thư viện Web Scraping. Điều này biến nó thành một ngôn ngữ lập trình hoàn hảo cho Web Scraping. Web Scraping Python chỉ yêu cầu vài dòng mã!
Trong hướng dẫn này, bạn sẽ được học từng bước cách tạo một Web Scraper đơn giản với Python. Ứng dụng này sẽ đi qua toàn bộ trang web, trích xuất dữ liệu từ mỗi trang và xuất chúng thành một tệp CSV. Trong hướng dẫn này, bạn sẽ tìm hiểu về những thư viện Python tốt nhất cho Data Scraping, những gì bạn nên sử dụng và cách sử dụng chúng. Hãy theo dõi hướng dẫn này từng bước và tìm hiểu cách tạo một script Python để Web Scraping.
Nội dung:
- Yêu cầu
- Các thư viện Python tốt nhất cho Web Scraping.
- Tạo một Web Scraper trong Python
- Kết luận
- câu hỏi thường gặp
Yêu cầu
Để tạo một Web Scraper Python, bạn cần những yêu cầu sau:
- Python 3.4+
- pip
Lưu ý rằng pip được bao gồm mặc định trong Python phiên bản 3.4 trở lên. Vì vậy, bạn không cần cài đặt nó bằng tay. Nếu bạn chưa cài đặt Python trên máy tính của mình, vui lòng làm theo hướng dẫn dưới đây cho hệ điều hành của bạn.
macOS
Trước đây, Python 2.7 đã được cài đặt sẵn trên Mac, nhưng không còn nữa. Phiên bản này đã lỗi thời và bạn cần cài đặt nó bằng tay. Hãy tải trình cài đặt và khởi động nó bằng cách nhấp đúp vào. Sau đó, hãy chạy trình trợ giúp cài đặt.
Windows
Hãy tải trình cài đặt Python và chạy nó. Trong quá trình chạy trình trợ giúp cài đặt, hãy chắc chắn rằng bạn chọn "Thêm python.exe vào PATH" như được hiển thị dưới đây:
Như vậy, Windows sẽ tự động nhận ra các lệnh python và pip trong dòng lệnh. Cụ thể hơn nữa, pip là một trình quản lý gói cho các gói Python.
Linux
Python đã được cài đặt sẵn trên hầu hết các bản phân phối Linux, nhưng có thể không phải là phiên bản mới nhất. Lệnh để cài đặt hoặc cập nhật Python trên Linux có thể khác nhau tùy thuộc vào trình quản lý gói. Ví dụ, trên các bản phân phối dựa trên Debian, bạn chạy lệnh sau:
sudo apt-get install python3Dù bạn sử dụng hệ điều hành nào đi nữa, hãy mở một cửa sổ terminal và đảm bảo rằng Python được cài đặt thành công:
python --versionKết quả sẽ tương tự như sau:
Python 3.11.0Bây giờ bạn đã sẵn sàng để tạo Web Scraper Python đầu tiên của mình. Nhưng trước tiên, bạn cần một thư viện Web Scraping Python!
Các thư viện Python tốt nhất cho Web Scraping
Bạn có thể tạo một kịch bản Web Scraping từ đầu với Python Vanilla, nhưng điều đó không phải là giải pháp lý tưởng. Cuối cùng, Python nổi tiếng với lựa chọn rộng lớn các gói và có nhiều thư viện Web Scraping khả dụng. Vậy hãy cùng xem những thư viện quan trọng nhất!
Requests
Thư viện Requests cho phép bạn thực hiện các yêu cầu HTTP trong Python. So với các thư viện HTTP chuẩn của Python, Requests giúp dễ dàng gửi yêu cầu HTTP. Requests đóng một vai trò quan trọng trong dự án Web Scraping Python. Điều này bởi vì bạn cần truy xuất dữ liệu được chứa trong một trang web trước khi có thể Scraping nó. Hơn nữa, bạn có thể cần gửi các yêu cầu HTTP bổ sung đến máy chủ trang web mục tiêu.
Bạn có thể cài requests bằng câu lệnh pip sau:
pip install requestsBeautiful Soup
Thư viện Beautiful Soup giúp thu thập thông tin từ các trang web. Beautiful Soup hoạt động với bất kỳ trình phân tích HTML hoặc XML nào và cung cấp tất cả những gì bạn cần để vòng lặp, tìm kiếm và thay đổi cây phân tích cú pháp. Hãy lưu ý rằng bạn có thể sử dụng Beautiful Soup với html.parser, phân tích viên được bao gồm trong thư viện tiêu chuẩn Python và cho phép cú pháp các tệp văn bản HTML. Bạn có thể sử dụng Beautiful Soup để trình duyệt trang web và trích xuất dữ liệu cần thiết từ đó.
Bạn có thể cài beautifulsoup4 bằng câu lệnh pip sau:
pip install beautifulsoup4Selenium
Selenium là một framework kiểm thử tự động mã nguồn mở tiên tiến, cho phép bạn thực hiện các hoạt động trên một trang web trong một trình duyệt. Nói cách khác, bạn có thể sử dụng Selenium để chỉ thị trình duyệt thực hiện một số tác vụ cụ thể. Hãy lưu ý rằng bạn có thể sử dụng Selenium làm thư viện Web Scraping cũng nhờ khả năng của nó làm việc với trình duyệt không đầu (headless browser). Nếu bạn không quen với khái niệm này: Headless Browser là một trình duyệt web chạy mà không có giao diện người dùng đồ họa (GUI). Khi Selenium được cấu hình ở chế độ không đầu, trình duyệt được kiểm soát sẽ chạy ở nền.
Bạn có thể cài selenium bằng câu lệnh pip sau:
pip install seleniumTạo một Web Scraper trong Python
Dưới đây là quá trình tổng hợp công cụ truyền thống:
- Trước tiên, bạn cần kết nối với URL mục tiêu.
- Tiếp theo, bạn cần phân tích tài liệu HTML trả về từ yêu cầu GET.
- Sau đó, bạn có thể chọn các phần tử HTML mà bạn quan tâm.
- Cuối cùng, bạn có thể trích xuất dữ liệu từ các phần tử đã chọn và lưu chúng theo định dạng mong muốn (CSV, JSON, v.v.).
Trước tiên, hãy cài đặt các thư viện mà chúng tôi sẽ sử dụng cho Web Scraping:
import requests from bs4 import BeautifulSoupNếu các thư viện đã được cài đặt thành công, hãy làm quen với quá trình Scraping:
# URL của trang chủ của trang web mục tiêu base_url = 'https://quotes.toscrape.com' # Khởi tạo headers để sử dụng cho yêu cầu GET dưới đây headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36' } # Nhận trang web mục tiêu và khởi tạo BeautifulSoup page = requests.get(base_url, headers=headers) soup = BeautifulSoup(page.text, 'html.parser') # TODO: Triển khai logic Scraping ở đây Sau khi có phần tử BeautifulSoup, bạn có thể bắt đầu Scraping. Lưu ý rằng quá trình Scraping bao gồm nhiều bước nhỏ, ví dụ: find(), find_all(), select(), v.v.
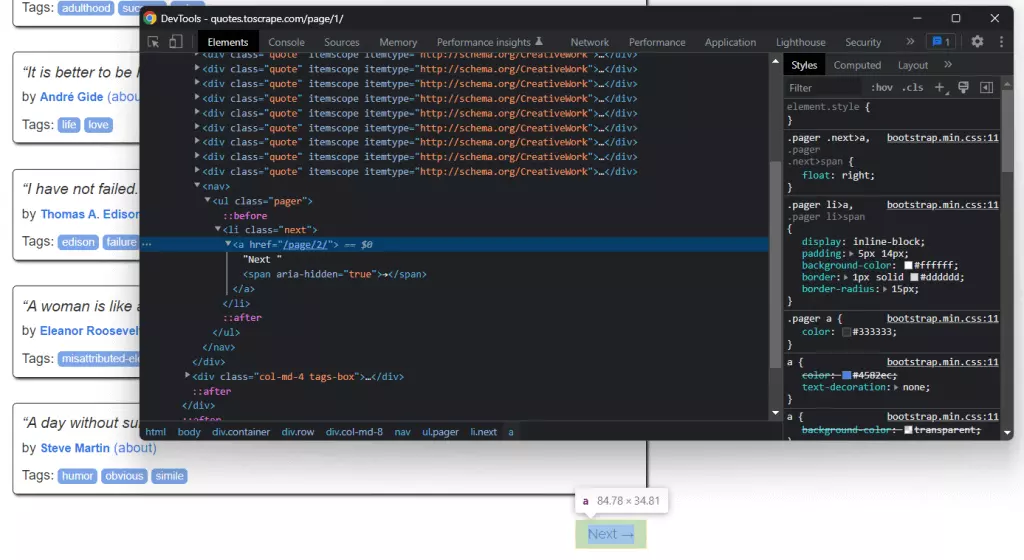
Đảm bảo tiếp cận logic Scraping phù hợp, bạn cần tìm hiểu cấu trúc DOM của trang web mục tiêu của bạn. Bạn có thể làm điều này bằng cách bấm chuột phải vào phần tử HTML tương ứng và chọn "Xem nội dung" hoặc tương tự. Việc này sẽ mở Developer Tools của trình duyệt bạn. Từ đó, bạn có thể xem nguồn HTML và tìm hiểu cấu trúc DOM.
Sau khi Scraping dữ liệu mục tiêu, bạn có thể lưu dữ liệu vào một định dạng nào đó, ví dụ: CSV, JSON, v.v. Ví dụ dưới đây lưu trữ dữ liệu vào một tệp CSV:
import csv # ... # Đọc tệp "quotes.csv" và tạo tệp nếu chưa tồn tại csv_file = open('quotes.csv', 'w', encoding='utf-8', newline='') # Khởi tạo đối tượng writer để chèn dữ liệu vào tệp CSV writer = csv.writer(csv_file) # Ghi tiêu đề của tệp CSV writer.writerow(['Text', 'Author', 'Tags']) # Ghi mỗi hàng của tệp CSV for quote in quotes: writer.writerow(quote.values()) # Kết thúc hoạt động và giải phóng tài nguyên csv_file.close()Cuối cùng, hãy chạy mã Python của bạn và kiểm tra tệp CSV kết quả. Nếu tất cả hoạt động đúng, bạn sẽ có tất cả 100 trích dẫn được chứa trong một tệp đơn đọc dễ hiểu!
Kết luận
Trong hướng dẫn này, bạn đã học cách Web Scraping hoạt động với Python, những gì bạn cần để bắt đầu bằng Python và những thư viện Python tốt nhất cho Web Scraping. Sau đó, bạn đã xem cách sử dụng Beautiful Soup và Requests để tạo một ứng dụng Web Scraping thông qua một ví dụ thực tế. Như bạn đã biết, chỉ cần vài dòng mã là đủ để Web Scraping bằng Python.
Câu hỏi thường gặp
Python có phải là một ngôn ngữ tốt cho Web Scraping không? Có, Python không chỉ tốt cho Web Scraping, mà còn được coi là một trong những ngôn ngữ lập trình tốt nhất cho mục đích này. Điều này liên quan đến tính đọc dễ hiểu và ít đòi hỏi về học hỏi. Hơn nữa, Python có một trong những cộng đồng lớn nhất trong thế giới IT và cung cấp một loạt các thư viện và công cụ cho Web Scraping.
Web Scraping và Crawling có phải là một phần của Khoa học dữ liệu không? Đúng, Web Scraping và Crawling là một phần của lĩnh vực rộng hơn của Khoa học dữ liệu. Scraping / Crawling đóng vai trò cốt lõi trong tất cả các thành phần khác nhau có thể được phát sinh từ dữ liệu có cấu trúc và dữ liệu không có cấu trúc. Điều này bao gồm phân tích, mô hình / kết quả thuật toán, nhận biết và "kiến thức có thể áp dụng".
Làm thế nào để Scraping dữ liệu cụ thể từ một trang web với Python? Khi Scraping dữ liệu từ một trang web với Python, bạn cần dò tìm trang web mục tiêu của mình, xác định dữ liệu mà bạn muốn trích xuất, viết mã trích xuất dữ liệu và thực thi nó và cuối cùng lưu dữ liệu theo định dạng mong muốn.